¶ 应试
¶ 成绩构成
数媒与大数据(据说软工不是TAT):
- 线上15分
- 慕课视频2分
- 讨论互动5分
- 作业8分
- 出勤与课堂表现(雨课堂)10分
- 实验15分
- 期末考试60分
你这一辈子就是被数媒害了,没法跟正经课程处事,跟兄弟复习的时候,总是在想,这课要是数媒的就好了;会在你硬盘里框框吃几十G的软件,下载安装的时候,总是在想,要是数媒上这个软件的课+实验就好了;坐在地下室地板编译sln的时候,他说进hololens看下,你的心怦怦跳,总是在想,要是等会看到的是“电量不足”怎么办?他要是卡的不行怎么办?然后数媒的课和实验选上了,吃掉了你90%的硬盘空间,编译、运行错误也不知道哪出了问题,你打开了文档,他沉默了一会说:
“该考计网了,朋友。”
¶ 考试题目
理论上:
- 单项选择题(每题1分,共10分),有两道英文题。
- 填空题(每空1分,共20分)
- 计算题(每题5分,共10分)
- 筒答题(每题5分,共15分)
- 论述题(每题10分,共30分)
- 综合题(共15分)
分数不需要踩点,能写多少写多少,尽可能详细一些。
可能会有“阅读材料”,但最多只会出现在选择填空里,知道就好。
¶ 知识点
不用信这里的加粗,画下来发现几乎全都是重点😅。
¶ 概述
- 计算机网络的定义、P2P
- 网络硬件(broadcasting、multicasting、unicasting、LAN、MAN、WAN、Internet、packet switching)
- 网络软件(protocol、layer、interface、service、错误控制、流量控制、面向连接与无连接的服务、可靠和不可靠的服务、服务与协议的关系、OSI参考模型、TCP/IP参考模型)
- 802协议、网络标准化
¶ 物理层
- 数据通信的理论基础(bandwidth、尼奎斯特定理,香农定理)
- 有导向的传输介质
- PSTN电话系统(Modem的调制方式(调幅;调频)、ADSL、干线与复用(FDM;WDM;TDM)、电路交换、分组交换、三种交换方式的比较)
¶ 数据链路层
- 成帧(位填充、字节填充)
- 错误检测和纠正(CRC)
- 基本数据链路协议(停等协议)
- 滑动窗口协议(捎带确认、发送窗口、接收窗口、一位滑动窗口协议、回退N、选择性重发协议)
¶ 介质访问子层
- 静态和动态信道分配
- 多路访问协议(ALOHA、CSMA、CSMA/CD、最小帧长、MACAW)
- 以太网(二进制指数后退算法,最小帧长、曼彻斯特编码、差分曼彻斯特编码、802.3帧格式)
- WLAN(隐藏站和暴露站问题、CSMA/CA、802.11 MAC子层协议)
- 数据链路层交换(网桥(散列表;flooding算法;逆向学习;动态拓扑结构变化)、生成树网桥、中继器、集线器、交换机、路由器、网关)
¶ 网络层
- 网络层设计要点(虚电路子网、数据报子网)
- 路由算法(最优化原则、sink tree、最短路径路由、距离矢量路由及无穷计算问题、链路状态路由、距离矢量路由和链路状态路由的比较、分级路由、广播路由、移动路由)
- 拥塞控制(RED)
- 服务质量(资源预留、缓冲、抖动、漏桶算法、令牌桶)
- 网络互连(隧道技术)
- Internet的网络层(IPv4协议、IP地址、子网、子网掩码、子网换分、CIDR、地址聚合技术、NAT、ICMP、ARP工作过程、DHCP、OSPF、BGP)
¶ 传输层
- 传输协议的要素(寻址、建立连接三次握手、释放连接三次握手、流控制和缓冲)
- UDP
- TCP(TCP服务模型、TCP协议、TCP连接建立、TCP连接释放、TCP滑动窗口协议、Nagle算法、愚笨窗口综合症、TCP拥塞控制、slow start)
¶ 应用层
- DNS
¶ 重点题型
¶ 名词解释
- 【2014】NAT
- 【2014】ADSL
- 【2014,2015',2019'】隧道技术
- 【2014,2015,2015',2016,2017,2019,2019"】带宽
- 【2014,2015,2015',2016,2017,2019,2019',2019"】协议
- 【2015,2015',2016,2019'】广播、组播
- 【2015,2016,2017,2019】汇聚树 (Sink Tree)
- 【2015,2016】多路复用
- 【2015',2019,2019"】TTL
- 【2017,2019,2019"】DNS
- 【2019'】抖动
¶ 选择填空题
记录一些逆天的选择填空题
-
【2014,2019'】计算机网络的目的是实现资源共享。
-
【2014,2019'】以太网帧(MAC)地址的长度是:48位。
-
【2014】服务质量用来描述网络能够提供的服务能力或网络应用的要求,网络中经常使用的服务质量参数有带宽、延迟、延迟抖动、丢失率等。
-
【2014】TCP 协议中校验和校验的范围包括TCP 头、数据和伪 TCP 头。
-
【2014】无线局域网对应的 IEEE 标准为IEEE 802.11,宽带无线网络对应的 IEEE 标准为 IEEE 802.16。
逆天玩意儿。
-
【2014】IP 协议中有一个TTL字段,用于限制分组在网络上的存活时间,避免分组无休止的在网络上循环。
-
【2023】释放连接的两种方式分别为非对称释放和对称释放,其中非对称释放方式容易丢失数据。
-
【2022】IP协议数据包最大载荷,经典以太网帧的最大长度、最小长度。
-
【2022】常用协议的端口号。
¶ 计算题
-
【2015,2017,2023】计算信道的最大传输速率。
-
【2014,2015,2017,2020,2022,2023】计算CRC校验。
看这篇学。
-
【2016】划分子网,通过子网掩码计算IP范围。
-
【2016,2017】Go-Back N协议需要重发的帧数。
-
【2017】分析使用了帧填充技术的一个帧片段哪里有问题。
挺抽象的这个。。
-
【2014,2017,2020,2022】给出一个比特串的调幅、调频、曼彻斯特编码和差分曼彻斯特编码。
-
令牌桶算法计算。
-
分组交换和报文交换延迟的计算。
-
最小帧长的计算。
-
【2017,2020】路由选择。
建议基于湖科大教书匠的路由选择协议进行学习。
¶ 简答题
- 【2015,2020,2022】漏桶和令牌桶。
- 【2016,2017,2020】虚电路交换和分组交换技术。
- 【2016,2017,2020】网桥/路由器/交换机的工作原理。
- 【2016,2022】DNS的工作原理。
- 【2015】路由协议、拥塞控制。
- 【2016,2017,2020】数据链路层的(特别是一位)滑动窗口协议。
- 【2023】列举一种帧边界定义方法(组合),并说明如果数据种出现该组合应该怎么办。
- 【2014,2023】二进制指数后退算法思想。
- 【2023】简述ARP协议的工作过程。
- 【2017,2020】NAT工作原理。
¶ 论述题
-
【2015,2023】滑动窗口协议。发送方如何对将要到来的帧的序列号和确定号赋值,接收方如何处理接收的帧的序列号和确定号。
-
【2015,2022,2023】关于拥塞控制,RED协议,TCP慢启动协议,二者的融合。
-
【2015,2017,2020】ARP,ARP工作过程(是否在同一个网络)。
-
【2016,2017,2020,2022】介质访问控制、以太网中、无线局域网中的协议。
-
【2016,2017,2020】路由器的动态路由算法(链路状态路由、距离矢量路由)、工作过程、IP协议如何解决环路问题、可靠的合理扩散。
-
【2017,2023】路由器地址聚合。
可以看这个地址聚合
-
【2016,2017,2020,2022】TCP协议,流量控制、拥塞窗口、确定发送速率、慢启动。
-
【2017】分别简述网络层和传输层使用的用于控制拥塞的机制。
¶ 综合题
- 【2023】TCP 接收窗口、拥塞窗口,TCP、IP、以太网帧封装,TCP分段,以太网帧填充字段
¶ 概述
本章介绍了计算机网络的一系列基本概念,主要包括:
- 网络划分:例如组播、广播,局域、广域网。
- 协议层次:协议、接口与服务之间的关系。
- 面向连接和无连接/可靠和不可靠:对网络服务的一些描述
- 参考模型:OSI 参考模型和 TCP/IP 参考模型。
其他的也很重要,但后面基本都会再次出现。
¶ 基本概念
计算机网络:是一个将分散的、具有独立功能的计算机系统,通过通信设备与线路连接起来,有功能完善的软件实现资源共享和信息传递的系统。
分布式系统:分布式系统是建立在网络之上的软件系统,有高度的内聚性和透明性。
内聚性:每一个数据库分布节点高度自治,有本地数据库管理系统
透明性:每个数据库分布节点对用户应用来说是透明的,用户感觉不到数据是分布的 Internet 是最著名的计算机网络,万维网是最著名的分布式系统,万维网(软件)运行于 Internet(硬件)上
VPN(虚拟专用网):一种可以将不同地点的单个网络联结成一个扩展网络的技术。
CS:由高性能计算机服务器和普通计算机客户机组成,服务器负责存储数据并处理客户请求,而客户机可远程访问服务器。
P2P(Peer to Peer network)对等网络:对等网络又称工作组,网上各台计算机有相同的功能,无主从之分,一台计算机都是既可作为服务器,设定共享资源供网络中其他计算机所使用,又可以作为工作站,没有专用的服务器,也没有专用的工作站。对等网络是小型局域网常用的组网方式。
它的作用在于,减低以往网路传输中的节点,以降低资料遗失的风险。
¶ 网络分类
根据传输模式,网络可以划分为:
-
广播(broadcasting):主机之间一对所有的通讯模式,网络对其中每一台主机发出的信号都进行无条件复制并转发,所有主机都可以接收到所有信息(不管你是否需要)。广播可以看成是一种特殊的组播形式。
-
多播/组播(multicasting):主机之间一对一组的通讯模式,也就是加入了同一个组的主机可以接受到此组内的所有数据,网络中的交换机和路由器只向有需求者复制并转发其所需数据。
主机可以向路由器请求加入或退出某个组,网络中的路由器和交换机有选择的复制并传输数据,即只将组内数据传输给那些加入组的主机。这样既能一次将数据传输给多个有需要(加入组)的主机,又能保证不影响其他不需要(未加入组)的主机的其他通讯。
-
单播(unicasting):主机之间一对一的通讯模式,网络中的交换机和路由器对数据只进行转发不进行复制。
根据网络的尺度,网络可以划分为以下几种:
-
个域网(PAN):允许设备围绕一个人进行通信。一个常见的例子是计算机通过无线网络与其外围设备链接。突出的技术就是蓝牙(bluetooth)。
-
局域网(LAN):一种局部地区的私有网络,一般在一座建筑物内或是建筑物附近,比如家庭、办公室或工程。具体分为有线和无线两种。
局域网有三个特点:距离短、传输速率高、错误率低。
局域网的组网方式有无线和有线两种:
- 无线LAN:每台计算机都有一个无线调制解调器和一个天线,用来和其他计算机通信。大多数情况下是和一个设备通信,这个设备称为接入点(AP, Access Point)、无线路由器或者基站。这个设备主要负责中继无线计算机之间的数据包,还负责中继无线计算机和 Internet 之间的数据包。代表技术就是 WIFI。
- 有线LAN:大多使用铜线作为传输介质,也有一些使用光纤。
许多有线局域网的拓扑结构是以点到点链路为基础的,俗称以太网的IEEE 802.3是迄今为止最常见的一种有线局域网。每台计算机按照以太网协议规定的方式运行,通过一条点到点链路链接到一个盒子,这个盒子称交换机(Switch),一台交换机有多个端口,每个端口连接一台计算机。交换机的工作是中继与之连接的计算机之间的数据包,根据数据包中的地址来确定这个数据包要发送给哪台计算机。
局域网的实现技术不止一种,例如在过去就使用过令牌环、FDDI和ARCNET等技术,只是在以太网(由802.3标准规定)推出后被逐渐取代。
-
城域网(MAN):范围覆盖一个城市。最著名的城域网例子是许多城市都有的有线电视网。
-
广域网(WAN):它能跨越很大的地理区域,通常是一个国家、地区或者一个大陆。
其中,广域网的任务是提供长距离通信,运送主机所发送的数据,其覆盖范围通常为几十到几千千米的区域,因而有时也称为远程网,广域网是因特网的核心部分;局域网使用广播技术,而广域网使用交换技术。
¶ 网络软件
¶ 协议层次结构
协议层次:为了降低网络设计的复杂性,大多数网络采用一堆互相叠加的层(layer / level)。每一层都建立在他的下层的基础之上,目的都是为其上层提供服务,而实现的具体细节则对上层隐藏。
其基本思想是,一段专门的软件(或硬件)向用户提供一种服务,而将内部的状态和算法的细节隐藏起来。相邻的层之间必须要定义接口(interface),以规定下层向上层提供哪些原语操作和服务。这个在进行网络设计时必须考虑清楚,这就需要每个层完成一组特定的有明确含义的功能。
层和协议的集合即称为网络体系结构(network architecture),一个特定的系统所使用的一组协议即称为协议栈(protocol stack)。
- 协议:通信双方就如何进行通信的一种约定。网络协议由语法、语义和同步三部分组成。
- 接口:是同一结点内相邻两层间交换信息的连接点,是一个系统内部的规定。接口定义了下层向上层提供哪些原语操作和服务。
- 服务:是指下层为紧相邻的上层提供的功能调用,由一组原语(primitive)构成的正式说明。
- 对等(实)体:不同机器上构成相应层次的实体称为对等(实)体。
此部分可以参考https://cloud.tencent.com/developer/article/1194830进行补充。
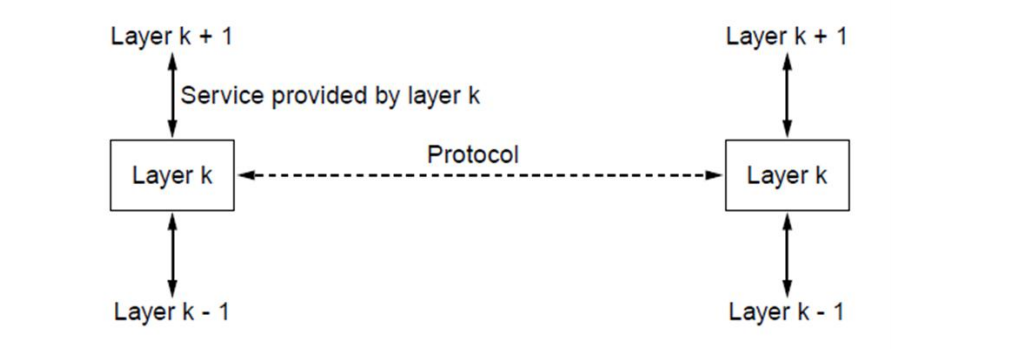
如上图所示,服务和协议都是“一组规则”(不准确),但是他们描述的分别是垂直关系和水平关系。服务和协议的关系:
-
服务是指某一层向它上一层提供的一组原语操作,服务定义了该层打算代表其用户执行哪些操作,但是他不涉及如何实现这些操作,服务也会涉及到两层之间的接口,其中底层是服务提供者,而上层是服务的用户(上下层之间的联系)。
-
协议是一组规则,用来规定同一层上的对等体之间所交换的消息或者分组的格式和含义。这些实体利用协议来实现他们的服务定义,他们可以自由的改变协议而不影响它提供给上层的服务(对等体之间的规范)。
¶ 差错控制与流量控制
差错控制(Error Control):是在数字通信中利用编码方法对传输中产生的差错进行控制,以提高数字消息传输的准确性。
流量控制(Flow Control):是指在发送端和接收端之间的点对点通信量的控制。流量控制所要做的就是抑制发送端发送数据的速率,以便使接收端来的及接收。
拥塞控制(Congestion Control):必须确保通信子网能够传送待传送的数据,是一个全局性的问题,涉及网络中所有的主机、路由器以及导致网络传输能力下降的所有因素。
¶ 面向连接服务与无连接服务
在计算机网络中,面向连接和无连接是两种不同的通信服务模式。面向对象的连接的服务是按照电话系统建模的,服务用户首先必须建立一个连接,然后使用连接传输数据,最后释放连接,本质上像一个管道;无连接的服务是按照邮政系统建模的,每一个报文都携带者完整的目的地址,每个报文都由系统中的中间节点路由,并且独立于后续的报文。
- 面向连接服务(connection-oriented service):通信双方必须先建立连接,分配相应的资源(如缓冲区),以保证通信能够正常进行,传输结束后释放连接和所占用的资源(连接建立,数据传输,连接释放)。
- 无连接服务(connectionless service):通信前双方不需要先建立连接,需要发送数据时就直接发送,把每个带有目的地址的包(报文分组)传送到线路上,由系统选定路线进行传输,是一种不可靠的服务。
二者的区别在于:
- 面向连接的要求建立连接,因而没有传输的数据没有必要再标明传输的目的地址;而无连接的则对每个报文都由独立的目标地址。
- 一般来说,面向连接的可靠性较高,协议相对复杂,传输的数据按照发送顺序到达;而无连接的可靠性较差,协议相对简单,常出现乱序,重复和丢失现象。
¶ 可靠与不可靠服务
可靠服务即从来不丢失数据的一种服务。一般情况下,可靠服务都要求接收方向发送方确认收到的每个报文;不可靠的服务则不会给发送方反馈任何确认消息,不保证数据不丢失。
- 可靠服务:是指网络具有纠错、检错、应答机制,能保证数据正常、可靠地传送到目的地。
- 不可靠服务:是指网络只是尽量正确、可靠地传送,但不能保证数据正确、可靠地传送到目的地,是一种尽力而为的服务。
二者之所以同时存在,原因在于:
- 在给定的层次可靠通信并不总是可以使用的。
- 为了提高可靠服务而导致的固有延迟可能是不可接受的。
需要注意:面向连接的服务只是在发送发和接收方之间建立连接,它并不能保证发送的数据流能准确无误的按序到达接收方。面向连接的服务同样分为可靠的面向连接服务和不可靠的面向连接服务。其中,前者主要包括报文序列、字节流,后者如数字化语音。
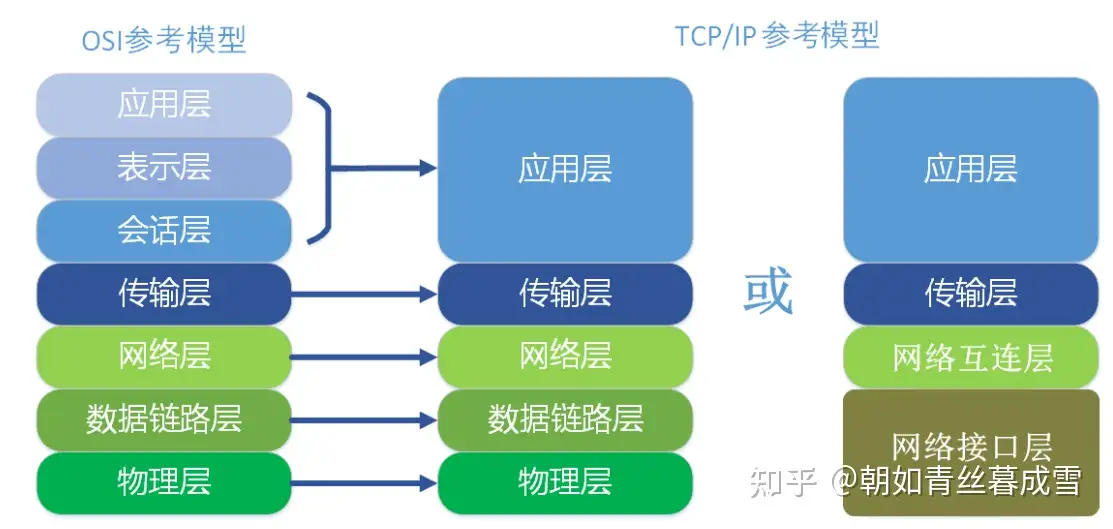
¶ OSI模型与TCP/IP模型
OSI(Open System Interconnect):开放式系统互联,一般都叫OSI参考模型。OSI模型分为七层,由低到高分别为:物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。如下图和下表所示:

| 名称 | 数据格式 | 功能 | 设备 |
|---|---|---|---|
| 物理层 | 二进制比特流 | 1) 相邻两节点之间,实现点到点的传输过程,2) 建立、维护和取消物理连接。 | 光纤、集线器、双绞线 |
| 数据链路层 | 数据帧 Frame | 保证相邻两节点之间的可靠传输,讲一个原始的传输设施转变成一条逻辑的传输线路。 | 交换机、网卡 |
| 网络层 | 数据包 Packet | 控制子网运行过程,确定传输路径。 | 路由器 |
| 传输层 | 数据段 Segment | 为网络层找到的路径提供可靠的传输。 | |
| 会话层 | 数据 Data | 允许不同机器上的用户之间建立会话。 | |
| 表示层 | 数据 Data | 关注所传递的信息的语法和语义,取消格式差异。 | |
| 应用层 | 数据 Data | 包含各种各样的协议。 |
TCP/IP协议划分了四层网络,自下而上分别为:
-
网络接入层/链路层:对应OSI参考模型中的物理层和数据链路层,负责监视数据在主机和网络之间的交换。该层主要有地址解析协议(ARP)工作。
事实上,TCP/IP本身并未定义该层的协议,而由参与互连的各网络使用自己的物理层和数据链路层协议,然后与TCP/IP的网络接入层进行连接。
-
互联网/网际互联/网络层:对应OSI参考模型中的网络层,解决主机到主机的通信问题。该层通过重新赋予主机一个IP地址来完成对主机的寻址,负责数据包在多种网络中的路由。该层主要有网际协议(IP)、互联网组管理协议(IGMP)和互联网控制报文协议(ICMP)在工作。
IGMP 是允许多个设备共享一个 IP 地址以便它们可以接收相同数据的协议,具体参见https://www.cloudflare.com/zh-cn/learning/network-layer/what-is-igmp/。
ICMP 的主要目的是报告错误。当两个设备通过互联网连接时,ICMP 会生成错误以与发送设备共享,以防任何数据未到达其预期目的地。详见https://www.cloudflare.com/zh-cn/learning/ddos/glossary/internet-control-message-protocol-icmp/
-
传输层:对应 OSI 参考模型的传输层,为应用层实体提供端到端的通信功能,保证了数据包的顺序传送及数据的完整性。运行了 TCP 和 UDP。
-
应用层:对应OSI参考模型的高层。
OSI 参考模型与TCP/IP 的关系如下图所示:
为了保证网络的互通性,各大国际组织根据自己所关注的领域制定了很多标准。这些标准总的来说可以分为软件协议标准和硬件连接标准这两大类。其中软件协议标准主要就是由 IETF 负责的 TCP/IP 协议族相关标准及应用层协议相关标准,硬件连接部分主要就是 IEEE 802 负责的相关标准。
**IEEE 802 的相关标准主要规定了数据链路层和物理层,且将数据链路层又分为了介质访问控制 (MAC) 层 和逻辑链路控制 (LLC) 层 这两层。**其中,前者负责控制网络中的设备如何获得对介质的访问权限和传输数据的权限,后者负责识别和封装网络层协议,并控制错误检查和帧同步。
这涉及到本教材中后面两个章节数据链路层和介质访问控制层的来源,二者都属于数据链路层。同时,本教材的参考模型是前一种TCP/IP,也就是区分物理层和数据链路层的版本。
OSI 参考模型和 TCP/IP 模型的相同点:
- 都是建立在协议栈概念上的,并且协议栈中的协议彼此相互独立。
- 两个模型中各个层的功能也大致相似。
不同点:
-
OSI采用的七层模型,而TCP/IP是四层结构。
-
TCP/IP参考模型的网络接口层实际上并没有真正的定义,只是一些概念性的描述。而OSI参考模型不仅分了两层,而且每一层的功能都很详尽,甚至在数据链路层又分出一个介质访问子层,专门解决局域网的共享介质问题。
-
OSI模型是在协议开发前设计的,具有通用性;TCP/IP是先有协议集然后建立模型,不适用于非TCP/IP网络。
-
OSI参考模型与TCP/IP参考模型的传输层功能基本相似,都是负责为用户提供真正的端对端的通信服务,也对高层屏蔽了底层网络的实现细节。
所不同的是 TCP/IP 参考模型的传输层是建立在网络互联层基础之上的,而网络互联层只提供无连接的网络服务,所以面向连接的功能完全在TCP协议中实现,当然TCP/IP的传输层还提供无连接的服务,如UDP;相反OSI参考模型的传输层是建立在网络层基础之上的,网络层既提供面向连接的服务,又提供无连接的服务,但传输层只提供面向连接的服务。
-
OSI参考模型的抽象能力高,适合与描述各种网络;而TCP/IP是先有了协议,才制定TCP/IP模型的。
-
OSI参考模型的概念划分清晰,但过于复杂;而TCP/IP参考模型在服务、接口和协议的区别上不清楚,功能描述和实现细节混在一起。
-
TCP/IP参考模型的网络接口层并不是真正的一层;OSI参考模型的缺点是层次过多,划分意义不大但增加了复杂性。
-
OSI参考模型虽然被看好,由于没把握好时机,技术不成熟,实现困难;相反,TCP/IP参考模型虽然有许多不尽人意的地方,但还是比较成功的。
OSI 模型的实力在于模型本身,TCP/IP 模型实力在于协议。
OSI 模型分为 7 层,明确区分了服务、接口和协议。OSI 模型中的协议具有更好的隐蔽性,也更加的通用。这个模型是在协议之前产生的,它的网络层同时支持无连接和面向连接的通信,但是传输层只支持面向连接的通信。
TCP/IP 模型分为 4 层,没有明确区分服务、接口和协议。通用性差,不适合描述非TCP/IP 网络。TCP/IP 模型是先有的协议后有的模型,协议和模型切合度高。TCP/IP 模型的网络层只支持无连接的通信,但是传输层同时支持两种。
¶ 参考模型各层的工作环境
这部分是对物理层和数据链路层的重新定义和说明。在课程中被放置在数据链路层,这里将内容提前,有助于理解物理层和数据链路层的定义和边界。
数据链路层通常作为网卡和操作系统驱动程序实现,网络层(IP协议所在层)通常是操作系统软件。
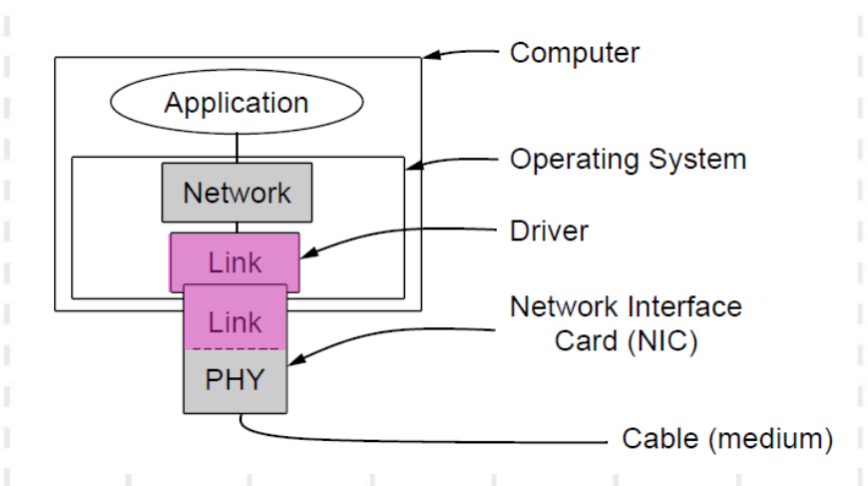
首先明确:网络层、数据链路层和物理层都是独立的进程。接下来,自下而上补充介绍各层的工作环境(五层TCP/IP模型):
- 【硬件实现】物理层的功能实现驻留在网络接口卡中,主要功能包括按照一定速率将数据转换为信号发送出去和将接收到的信号转换为数据。
- 【硬件实现】数据链路层的功能实现部分分布在网卡中,部分分布在操作系统中。网卡中的数据链路层功能主要包括对发送的数据生成校验和,对接收的数据检查校验和。
- 【硬件实现】网卡上发送和接收的数据都存放在一个缓冲区中,由网卡上的物理层和数据链路层进程使用。
- 【软件实现】数据链路层的部分功能在操作系统中实现,主要包括可靠性和高效性所涉及的各种功能。如重传、确认、编号、流量控制、流水等。
- 【软件实现】网络层的功能也在操作系统中实现。
- 【软件实现】操作系统中发送和接收的数据都存放在操作系统管理的缓冲区中,由位于操作系统中的数据链路层和网络层进程使用。
- 【软件实现】应用层有单独的缓冲区。数据需要在应用层缓冲区和操作系统缓冲区交换数据。
结合以上七点,可以发现:
- 该协议栈中提到三个缓冲区,他们分别是:
- 网卡的缓冲区:网卡上发送和接受的数据,由物理层和数据链路层共同使用。
- 操作系统的缓冲区:操作系统中发送和接受的数据,由数据链路层和网络层共同使用。
- 应用层缓冲区:单独的缓冲区,需要喝操作系统的缓冲区交换数据。
- 数据链路层横跨网卡和操作系统。在网卡中,功能包括生成和检查校验和;操作系统中,包括重传、确认、流量控制等可靠性和高效性的设计。
- 网卡和操作系统的功能基本如下:
- 网卡:(数据链路层的)生成、检查校验和;发送和接收数据。
- 操作系统:(数据链路层的)差错控制和流量控制;网络层的功能;和应用层交换数据。
在这种条件下,将网卡中的功能合并统称为物理层,操作系统中的功能合并成为数据链路层。所以,数据链路层协议不再关心校验和的生成和检查的具体实现,而是使用一种事件方式提供网卡操作的结果。
¶ 802协议与网络标准化
IEEE 802中定义的服务和协议限定在OSI 模型的最低两层(即物理层和数据链路层)。事实上,IBBE 802 将OSI 的数据链路层分为两个子层,分别是逻辑链路控制(LLC,Logical Link Control)和介质访问控制(MAC,Media Access Control)。几种重要的802协议:
- 802.3:以太网介质访问控制协议(CSMA/CD)及物理层技术规范。
- 802.11:无线局域网的介质访问控制协议及物理层技术规范。
- 802.15:个域网协议(蓝牙、ZigBee)。
- 802.16:宽带无线网。
世界上有很多的网络生产商和供应商,他们都有自己的思维模式和行为方式,只有大家都遵守一些网络标准才能进行协调,相关的组织有:
- ISO 国际标准化组织
- 国际电信联盟 ITU
- 电气电子工程师协会 IEEE
- Internet 工程任务组 IETF
- Internet 研究任务组 IRTF
¶ 物理层
计算机网络中的物理层是网络协议栈中的最底层,负责传输比特流(bitstream),通过物理媒介进行通信。它处理的是关于如何在物理媒介上传输数据的问题,包括传输介质、电气特性、物理连接和数据传输速率等。
物理层的主要功能包括(这些东西的确都会在课程里介绍):
- 传输介质:物理层确定了数据在网络中传输的物理媒介,可以是铜线、光纤、无线电波等。它定义了传输介质的特性,如传输速率、带宽和传输距离等。
- 电气特性:物理层定义了数据在传输介质上的电气特性,包括电压、电流、时序等。这些特性确保了数据能够正确地在传输介质上传输和接收。
- 编码和调制:物理层负责将数字数据转换为适合传输介质的模拟信号或数字信号。编码技术可以包括将比特流映射到信号的不同电平或频率,以及添加同步位和校验位等。
- 物理连接:物理层定义了设备之间的物理连接方式,包括连接器、接口和电缆类型等。它确保设备能够正确地连接并进行数据传输。
- 时钟同步:物理层需要确保发送方和接收方的时钟保持同步,以便在正确的时间进行数据传输和接收。
- 基本的数据传输:物理层负责将数据从发送方传输到接收方,通过控制比特流的传输速率、传输模式(全双工、半双工)和数据的流向等。
¶ 数据通信理论基础
每个给定的信道都有一定的数据传输能力,如何描述和定义这种数据传输能力是本节主要的关注点。信道的传输能力可以使用带宽和信道描述:
- 带宽(Bandwidth):在传输中不会明显减弱的频率的宽度,通常引用的带宽是指从到使得接收能量保留一半的那个频率位置,是传输介质的一种物理属性。通常取决于介质的构成、厚度、电线或者光纤的长度。
- 信道:信道是信号的传输媒介。信号在任何物理通道传输的过程中会有能量的损失,尤其是不同频率的信号损失程度不同;频率越高的信号损失能量越多。给定一个传输介质,频率高的一些信号成分无法传输到接收方(传输过程中消耗完了)。
信号在信道内传输时,信号会包含一种或多种频率成分。其中高于信道截止频率的频率成分将由于能量衰减过多而不能通过信道,通过信道的只能是低于截止频率的成分。传输过程中信号会发生变形,能否准确识别依赖于通信双方的约定(信号发送设备和信号接收设备的):通信双方需要根据能够传输过去的频率成分考虑合适的调制(编码)和解调制(解码),即什么样的信号对应什么样的比特(组合)。
信噪比(SNR):信号功率与噪声功率 的比值,即为信噪比 。
分贝(dB):通常把信噪比表示成对数的形式,对数的取值单位称为分贝。 信噪比为100可表示为 20dB。
一些术语:
- 码元(Symbol):承载信息量的基本信号单位。显然, 级码元需要的比特数(bits)有关系
- Baud Rate:码元传输速率,单位为波特(Baud),即每秒传输的码元数。
- 比特率(Bit Rate):单位时间内传输的比特数,单位为比特/秒(bps)。比特率与码元传输速率的关系为:。这里的就是上面的比特数。
¶ 信道的最大数据传输速率
计算信道的最大数据传输速率可以使用尼奎斯特定理(Nyquist theorem)和香农定理(Shannon theorem)。
-
尼奎斯特定理:用来表示一个有限带宽的无噪声信道的最大数据传输率。尼奎斯特定理用于计算理想情况下的最大数据传输速率,即在没有噪声干扰的情况下。根据尼奎斯特定理,信道的最大数据传输速率可以通过以下公式计算:
其中, 表示最大数据传输速率(单位为比特/秒), 表示信道的带宽(单位为赫兹), 表示信号的离散级数(即离散的幅度或相位级数)。
尼奎斯特定理告诉我们,通过增加信号的离散级数或者扩大信道的带宽,可以提高信道的最大数据传输速率。
例如,如果一个无噪音话音信道(3400 Hz),采用二进制信号传输,V=2,最大速率不能超过。若V = 16,最大速率则可提高到 27200 bps。
-
香农定理:用来表示有噪声信道的最大数据传输率或容量。香农定理用于计算在存在噪声干扰的情况下的最大数据传输速率。根据香农定理,最大数据传输速率可以通过以下公式计算:
其中, 表示最大数据传输速率(单位为比特/秒), 表示信道的带宽(单位为赫兹), 表示信号与噪声的比值(信噪比)。
香农定理告诉我们,通过增加信道的带宽或提高信号与噪声的比值,可以提高信道的最大数据传输速率。
例如,模拟电话系统中,话音信道信噪比的典型值为 30dB(或者说因为,所以),那么最大数据传输速率为: 。
¶ 传输介质
常见的有线传输介质如下:
- 磁介质:带宽良好,延迟高。
- 双绞线:将两根线绞在一起,噪音对他们的干扰是一样的,所以他们的电压差不会改变,通过电压差来表示信号。双绞线的工作方式有三种:
- 全双工:可以同时双向使用。
- 半双工:可以双向传输,但每一时刻只允许使用一个方向。
- 单工:只允许单向传输。
- 同轴电缆:带宽高,抗噪性好。
- 电力线
- 光纤:分为单模和多模两种。
¶ 调制和编码
在信号传输过程中,数据(Data)是指传递(携带)信息的实体,信息 (Information)则是数据的内容或解释。数据可以分为模拟(Analog)数据与数字(Digital)数据。
信号(Signal)是数据的物理量编码(通常为电编码 ),数据以信号的形式传播。信号包括模拟信号与数字信号,还可以分为基带(Base band)信号与宽带(Broadband )信号。
通信系统的传输过程中,通信系统把携带信息的数据用物理信号形式通过介质传送到目的地。
信息和数据(0、1比特)不能直接在介质上传输。
通信系统自下而上由信道、信号、数据三个概念组成。首先是信道,分为数字信道和模拟信道:
- 数字信道:以数字脉冲形式(离散信号)传输数据的信道。
- 模拟信道:以连续模拟信号形式传输数据的信道。
与信道相似,信号包括模拟信号和数字信号:
- 模拟信号:时间上连续,包含无穷多个值。
- 数字信号:时间上离散,仅包含有限数目的预定值。
数据也有模拟数据和数字数据组成,其中数字数据的传输过程有两种:
-
基带传输:不调制,编码后的数字脉冲信号直接在信道上传送。
例如以太网。
-
频带传输:调制成模拟信号后再传送,接收方需要解调。
例如通过电话模拟信道传输。
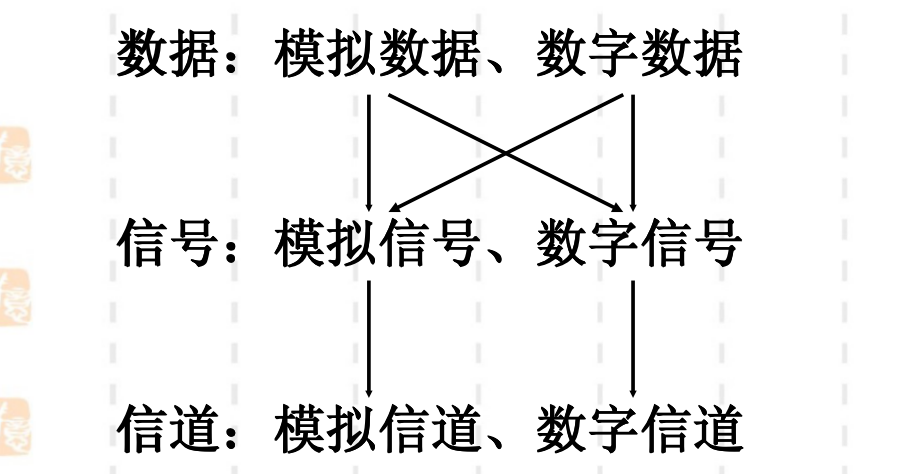
如上图所示,不同类型的信号在不同类型的信道上传输有4种组合,每一种相应地需要进行不同的编码处理。组合情况如下图所示:
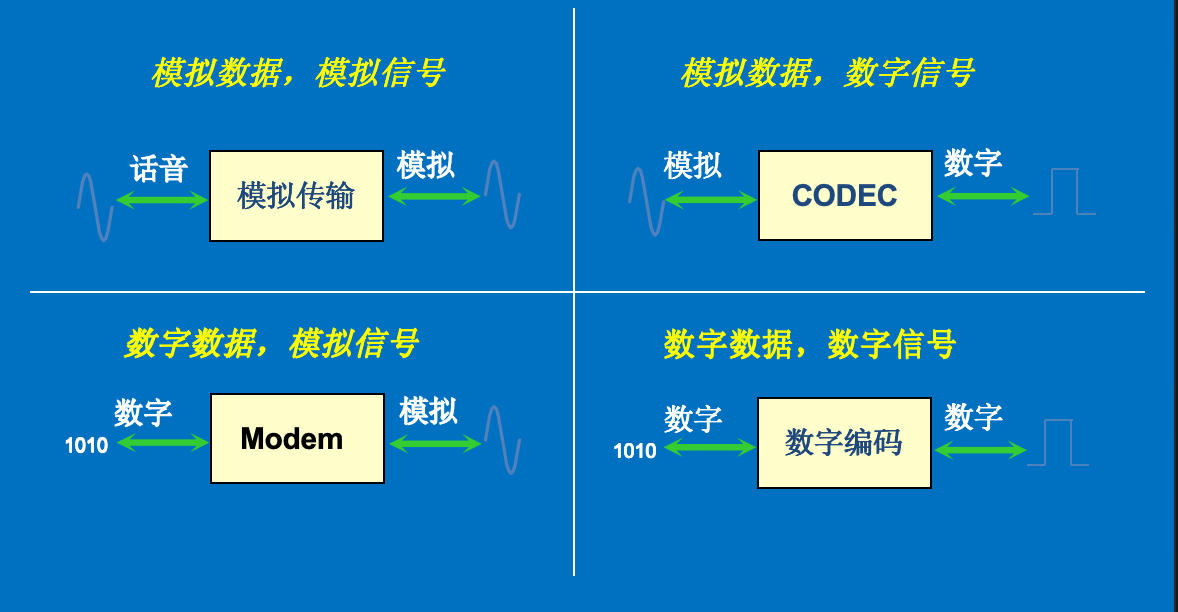
在四种传输过程中可以分为两种操作:
- 编码:用数字信号承载数字或模拟数据。
- 调制:用模拟信号承载数字或模拟数据。
¶ 编码
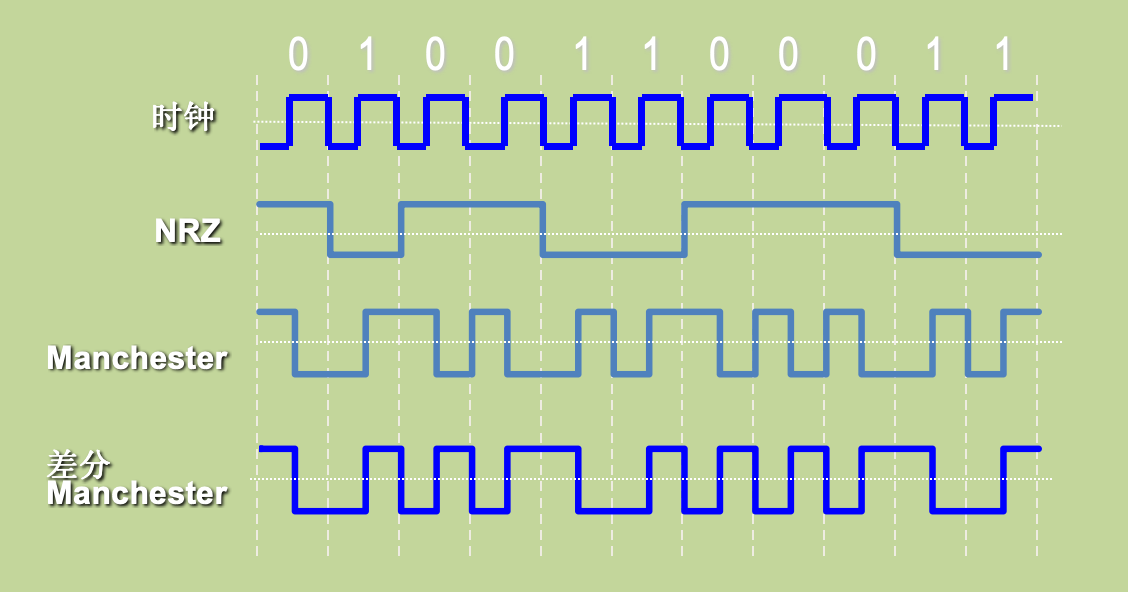
数字数据的编码是一块比较重要的内容,会在计算题中考察曼彻斯特编码等问题。三种主要的数字编码为:
-
不归零制(Non-Return to Zero):二进制数字0、1分别用两种电平来表示(常用-5V表示1,+5V表示0)。
所谓的“Non-Return to Zero”,即在连续的 1 或 0 序列中,信号电平不会发生变化。这与其他一些编码方案不同。
缺点: 不具备自同步机制,必须使用外同步。
-
曼彻斯特编码(Manchester Code):使用电压的变化来表示0和1,规定在每个码元的中间发生跳变。高到低的跳变视作0,低到高的跳变视作1。
因为每个码元中间都要发生跳变,接收端可将此变化提取出来作为同步信号,使接收端的时钟与发送设备的时钟保持一致,所以曼彻斯特编码也称为自同步码(Self-Synchronizing Code)。它具有自同步机制,无需外同步信号。
但是需要双倍的传输带宽,也就是信号速率是数据速率的两倍。
-
差分曼彻斯特编码(Differential Manchester Code):与曼彻斯特编码相同,在每个码元的中间,信号都会发生跳变。不同之处在于用在码元开始处有无跳变来表示0和1,码元开始处有跳变为0,无跳变为1。
DMC 的关键特点是使用了差分编码,即每个位的编码取决于前一个位的值。这样做的好处是消除了对绝对电平的依赖,使得信号更加抗干扰。另外,由于每个位都有信号电平的变化,可以实现时钟同步,接收方可以根据信号的电平变化来恢复数据。
¶ 调制
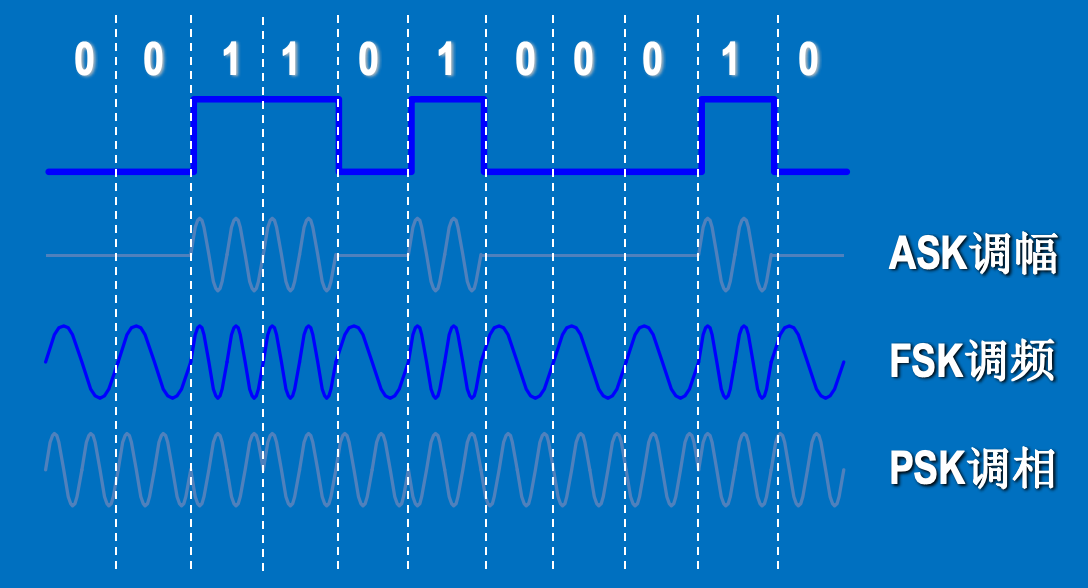
数字信号的调制编码也有三种:
- 调幅(Amplitude Shift Keying, ASK):用载波的两个不同振幅表示0和1。
- 调频(Frequency Shift Keying, FSK):用载波的两个不同频率表示0(1.2KHz)和1(2.4KHz)。
- 调相(Phase Shift Keying, PSK):用载波的起始相位的变化表示0 (同相)和1(反相)。
所谓 Keying,就是调制信号的过程。
¶ 多路复用
复用:多个信息源共享一个公共信道。如下图所示:
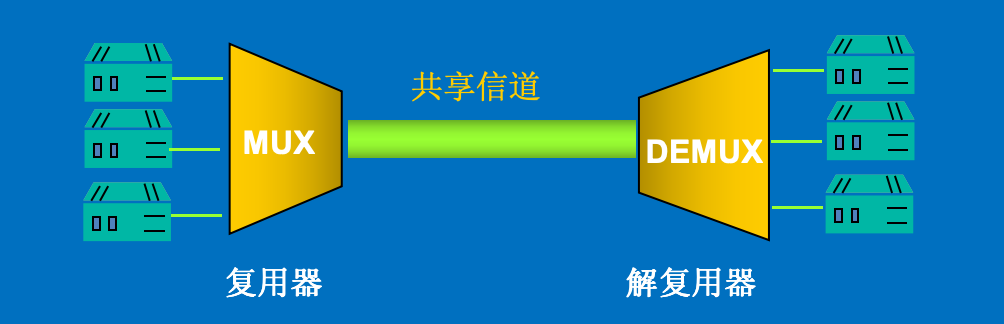
复用的类型有如下几种:
-
频分复用(FDM,Frequency Division Multiplexing):将整个传输频带被划分为若干个频率通道,每个用户占用一个频率通道。频率通道之间留有防护频带。适用于模拟信号的传输。

比如说,可以排列多个频段,每个频段4K(包含3.4K数据和0.6K间隔)
-
波分复用(WDM,Wave Division Multiplexing):将整个波长频带被划分为若干个波长范围,每个用户占用一个波长范围来进行传输。适用于光纤传输。

本质上 WDM 当然也是 FDM 的一种,因为波长不同的光,频率也是不同的。所以,WDM 可以看成一种很高频的 FDM。
-
时分复用(TDM,Time Division Multiplexing):把时间分割成小的时间片,每个时间片分为若干个通道(时隙),每个用户占用一个通道传输数据。 适用于数字信号传输。

¶ PSTN
PSTN ,Public Switched Telephone Network 是一种常用的旧式电话系统,提供的是一个模拟的专用通道,通道之间经由若干电环交换机连接而成,当两台主机或路由器需通过PSTN 连接时,必须在网络接入侧使用调制解调器实现信号的模数/数模转换。
电话系统的组成:本地回路、干线(多路复用)和交换局(交换机、交换技术如虚电路交换和分组交换等)。
PSTN作为早期用户接入互联网的主要方式,包含了现代网络中的一些主要思想和概念。
P.S. 许多人可能不知道,在过去(大概05年以前)是通过将电话线插到Modem(调制解调器,但并不是现在的光信号调制解调器)来上网的,这时候还需要在计算机上通过一些程序进行拨号操作,这种方式就是PSTN。
¶ 本地回路
本地回路关注如何使用模拟信号尽可能快速的传递数据。主要设备是调制解调器(Modem),调制是将数据转换为模拟信号,解调制是将模拟信号转换为数据。根据发展历史,modem 可以分为使用4K带宽的电话调制解调器和使用1.1M带宽的宽带调制解调器(ADSL调制解调器)。
- 电话调制解调器使用电话的4K带宽,所以电话和数据传输不能同时进行。
- 非对称数字用户线(ADSL,Asymmetric DSL)调制解调器使用本地回路的全部1.1M带宽,电话和数据传输能够同时进行,不过ADSL的上行和下行带宽不对称(下行速率大于上行速率,因为大多数用户下载数据量超过上传)。ADSL采用FDM 把普通的电话线分成电话、上行和下行三个相对独立信道,从而避免相互之间的干扰。
- 光纤到户将本地回路升级为光纤,使用光信号传递数据。每大约100个用户的光纤通过分离器/组合器复合到一根到端局的光纤上,用户之间通过时分多路复用使用到端局的光纤。
ADSL分为256条信道,0 信道用于简单老式电话服务,1-5 不用防止语音信号与数据信号相互干扰,剩余的 250 个信道中两条分别用于上行流和下行流控制,剩余全部是用户数据。但是一般将 80% ~ 90% 的带宽分配给下行信道(也就是通常有8Mbps下载,就会有1Mbps上传)。
¶ 干线与复用
中继线是电话系统中的骨干线路,用于连接不同层次的交换局,使用数字信号传输。现在的中继线一般为光纤,能够同时支持多路电话呼叫,采用的主要技术是多路复用技术。这里的多路复用技术也是包括:
- FDM(频分多路复用)
- WDM(波分多路复用)
- TDM(时分多路复用)
¶ 交换
交换局内主要设备是交换机(交换节点),交换机连接多条线路,主要功能是把一条入境线路上来的呼叫交换到一条出境线路上,从而支持呼叫一直到接收方。
这部分的内容与网络层的分组是一致的。
-
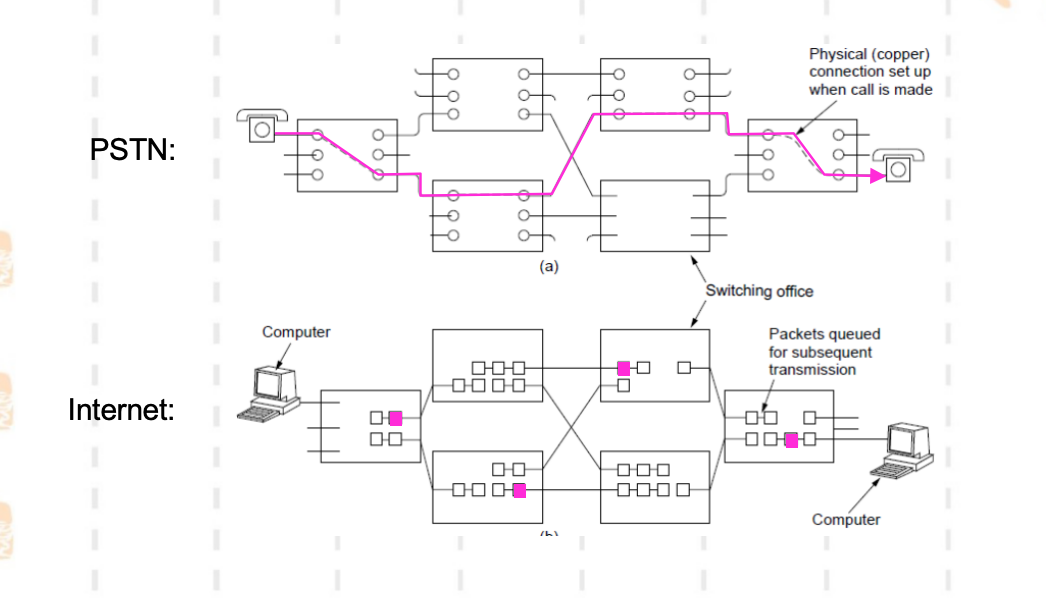
(虚)电路交换:一种面向连接的工作方式,交换设备在通信双方找出一条实际的物理线路的过程。分为三步:使用前建立一条从发送方到接收方的路径;使用这条路径传输;传输完毕释放路径。
其特点是建立连接的时间长、一旦建立连接就独占线路,线路利用率低、无纠错机制、建立连接后,传输延迟小。
最早的电路交换连接是由电话接线员通过插塞建立的,现在则由计算机化的程控交换机实现。
-
包/分组交换:一种非连接的工作方式。数据被分为多个包(分组),每个包包含完整的目的地址。每个包经过交换节点时,交换节点按照当前网络状况(交换表)为其选择一条输出线路。此过程一直持续直到包被传送到目的地。
PSTN使用(虚)电路交换,因特网使用分组交换,如下图所示:
¶ 数据链路层
数据链路层是计算机网络中自上而下的第二层。在第一层物理层中,关注的重点在于传输介质和数据的编码等问题上,最终实现了数据的传输,这种通信主要由网卡(其实还包括操作系统的一部分)硬件完成。
但是物理层提供的数据传输是不可靠的。在物理层中只定义了编码方式、复用方式的规则,却没有规定数据如何传输与接受、如何处理传输中的错误、如何确保数据不重不漏,数据链路层就完成了对传输过程的一系列定义,得到相邻机器之间的可靠高效的数据通信。
物理层和数据链路层都是由802协议规定的,包括802.3、802.11等一系列协议。
值得注意的是,数据链路层被802.3协议进行了细分,分别为介质访问控制子层(MAC Layer)和逻辑链路控制层(LLC Layer),MAC靠近物理层。
¶ 介绍
利用物理层提供的不可靠的比特传输服务(功能),在两台相邻机器之间实现可靠高效的数据通信的算法和协议。或者可以说成将一条不可靠的物理线路(line)通过协议提升为一条可靠的数据链路(data link)。这其中有三个值得注意的关键词:
- 相邻:两台机器之间通过一条信道连接起来,按序到达是其固有特性。
- 可靠:接收方接收到的数据和发送方发送的数据一致。
- 高效:充分利用信道的带宽(传输能力)。
可靠性主要包括两个方面的内容:差错控制和流量控制。差错控制是为了克服线路误差带来的传输错误;流量控制是为了避免快速的发送方淹没慢速的接收方。
淹没:指发送方发送的太快,使得接收方来不及接收所有的数据,造成数据的丢失。
高效性主要指能够充分利用线路的带宽,主要是克服线路延迟给可靠传送数据带来的限制。
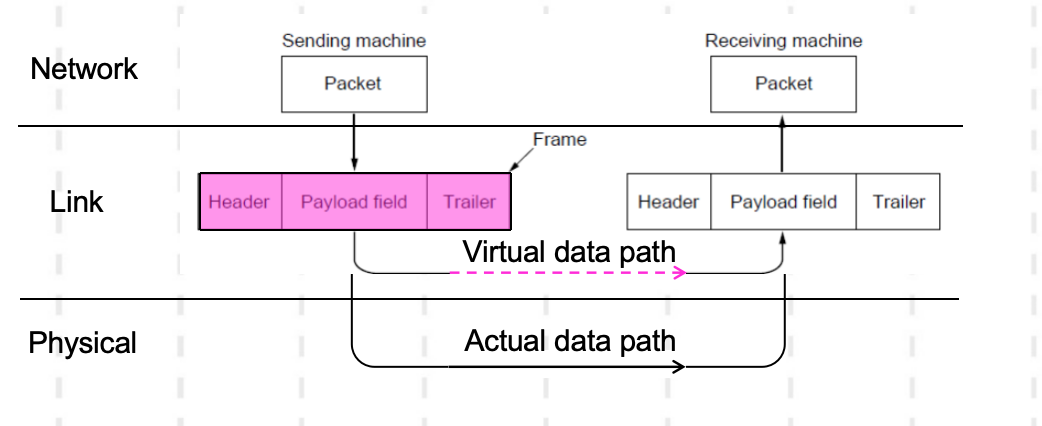
数据链路层从网络层获取数据包,将其封装为“帧头+有效载荷+帧尾”的帧(Frame),数据链路层的核心就是帧的管理。
帧:数据链路层对等体之间交换的协议数据单元。关于帧,有这些需要知道的内容:
- 由发送方实体将从网络层接收到的分组添加额外的字段(协议字段)封装而成。
- 接收方实体根据协议字段的取值执行相应的操作(协议算法)。
- 判定接收的数据正确后,最终将协议字段去掉,将分组提交给自己所在设备的网络层。
- 帧的长度是有限制的。每个传输线路都有一定的差错率,帧的最大长度限制是为了让一个帧在传输过程中出现差错这个现象成为“小概率事件”,从而易于处理出错的帧。在网络中经常使用重传处理差错。
数据链路层,可以提供三种可能的服务(就是第一章中提到的有/无连接、可靠/不可靠服务):
- 无确认的无连接服务。
- 有确认的无连接服务。
- 有确认的有连接服务。
显然,一般来说不存在无确认的有连接服务,因为无确认直接违背可靠传输的基本原则。没有确认帧,发送方无法得知数据是否正确接收,也无法进行重传或纠错。因此,无确认的有连接服务无法提供可靠性,不符合数据链路层提供可靠服务的目标,也就不存在无确认的有连接服务。
¶ 差错控制
在数据链路层,接收方实体需要判断接收的帧是否在传输过程中出现了错误。如果没有传输错误,则将帧中包含的分组提交给网络层;否则,需要发送方重传这一帧。帧的数据取值可能没有任何特征,这时需要添加额外的位来凑出某种或某几种特征,通过检验特征是否存在来判断数据传输是否正确。
校验和:通信双方为了对传输的数据进行检错和纠错而根据一定的规则添加的额外的位(组合)。
例如,单个奇偶校验位(Single Bit Parity),不论是奇校验还是偶校验,EDC(即 Error Detecting Code)长度为 1 bit。
校验和是可以用来进行纠错的。
话虽如此,须知校验和相同只能说“没有检测到错误”,但却并不能保证没有错误。也就是说,在某些情况下,可能传输真的发生了错误,但是校验和不变。
重传是检测到差错之后重要的纠错方式。在实际的网络环境下,出于性能的考虑不会使用校验和纠错,而是直接要求另一方重发相应的包。重传的相关概念:
-
重传:当某一帧在传输过程中出现错误时,网络中常用的处理方法是发送方重传这一帧,而不是接收方使用纠错算法纠正错误。
重传对发送方有资源要求,即保存自己所发送过的帧,需要时重新发送一次。只有当一帧被接收方正确接收并将帧中分组提交给网络层后,才认为这一帧的传递任务结束,才能清空保存这一帧的缓冲区。
-
确认:接收方对自己所接收正确的帧回复一个确认,使得接收方也能知道这一帧已经被正确传输。
有了确认机制后,发送方如果收到一帧的确认,则认为这一帧已经被正确传递,并且接收方也这样认为(否则不会发回确认),那么这一帧的传递结束,清空这一帧所使用的资源;如果发送方没有收到一帧的确认,则需要重传这一帧。
-
重传定时器:为了避免发送方长时间地等待确认,根据线路延迟等要素估计一个确认能够返回的时间,设置为重传定时器。当等待时间超过这个时间时,则认为确认无法回来,重发这一帧。
在定时器超时时一帧的确认没有回来,发送方只能认为接收方没有发回确认,也只能推断接收方没有收到正确的这一帧。所以选择重传这一帧。
-
编号:为每个传递的帧确定一个编号,从而区别不同的帧。
当接收方收到一个已经接收过的编号的帧时,则认为是重复帧,直接丢弃这一帧,但要回复一个这一帧的确认(因为接收方在等待这一帧的确认)。
¶ 流量控制
流量控制用于防止快速的发送淹没低速的接受者。流量控制是可靠性传输的必要条件;不可靠的传输有时也需要流量控制。
常见的流量控制机制有两种:
-
基于反馈的流量控制(隐式,非明确指明)。
-
基于速率的流量控制(显示,明确指明)。
基于速率的流量控制通过显式限制发送方的发送速率实现。
流量控制技术中保证高效性的三个方式:
- 流水发送:为了避免一帧传递完后再传递下一帧带来的线路带宽的浪费,尤其是在线路较长时, 发送方可以流水发送多帧。这需要发送方有多个缓冲区来缓存已经发送还没有收到确认的帧(没有传输完成的帧)。
- 捎带确认:为了避免单独的确认帧浪费资源,将确认使用接收方发送的数据帧携带。这要求双工通信。
- 批量确认:在流水场景中,接收方收到多个帧时返回一个确认,从而减少确认帧的个数。尽最大可能不触发己正确接收帧的重传。
¶ 成帧
成帧的主要工作是将每一段来自上层的数据封装起来,使得数据链路层的接收方实体能够正确识别一个帧的开始和结束(能够确定帧的边界),并能依据帧中携带的各种控制字段(额外添加的协议字段)判断所接收帧的正确性(是否在传输过程中出错、是否是想要的那一帧)。
确定帧的边界有一些基本的要求:容易识别一个帧的开始和结束(出错时容易同步);开销尽可能少。
成帧有四种主要的方法:
-
字节计数法:利用头部中的一个字段来标识该帧中的字符数。当目的节点的数据链路层收到字节计数值时就知道后面跟随的字节数,从而可以确定帧结束的位置。
问题:如果计数字段出错,即失去了帧边界划分的依据,接收方就无法判断所传输帧的结束位和下一帧的开始位,收发双方将失去同步,从而造成灾难性的后果。
-
字节填充的标志字节法:使用一些特定的字符来界定一帧的开始与结束。发送方的数据链路层在数据中“偶尔”出现的每个标识字节的前面插入一个特殊的转义字节(ESC)。接收方的数据链路层在将数据传递给网络层之前必须删除转移字节,这种技术成为字节填充。
-
比特填充的标志比特法:使用一个特定的比特模式,即
01111110来标志一帧的开始和结束。为了不使信息位中出现比特流01111110被误判为帧的首尾标志,发送方的数据链路层在信息位中遇到5个连续的1时,将自动在其后插入一个0;而接收方做该过程的逆操作,即收到5个连续的1时,则自动删除后面紧跟的0,以恢复原信息。问题:采用2、3两种方法时,一帧的长度要取决于它所携带的数据内容。
-
物理层编码违例法(曼彻斯特编码):使用“不会出现在常规数据中”的余比特作边界。好处是除了开始和结束的填充外, 不再需要填充额外的数据。
令 Bit “1” 表示高-低电平对,Bit “0” 表示低-高电平对,帧的边界(高-高,低-低),这样就行了
¶ 错误检测和纠正
¶ 海明码
一般不考。
海明码是一种多位奇偶校验码,可以检测和纠正多位错误。海明码的基本思想是在数据位后面添加校验位,使得数据位和校验位的个数之和为2的幂次方。海明码的校验位的个数是数据位的个数加上1,2,4,8,16...,即1,2,4,8,16...个校验位。
举例:
信息码为1 1 0 0 1 1 0 0,k=8。
-
插入冗余码(位置是2的幂次)
1 2 3 4 5 6 7 8 9 10 11 12 A B 1 C 1 0 0 D 1 1 0 0 -
找线性码。
以A为例:它是位,而“包含了”这个位的有:
- A本身
- 第三码字()
- 第五码字()
- 第七码字()
- etc.
所以A的线性码是
1 3 5 7 9 11;以B为例:它是位,而“包含了”这个位的有:
- B本身
- 第三码字()
- 第六码字()
- 第七码字()
- etc.
所以B的线性码是
2 3 6 7 10 11。 -
将线性码所在的码位相加(二进制不进位加法,其实就是异或),即可求出满足偶校验的冗余码的值。
例如,C的线性码是
4 5 6 7 12,所以处理的序列就是C 1 0 0 0,因此为了该序列满足偶校验,冗余码C的值就是1。 -
填入冗余码的值,得到最终的海明码。
1 2 3 4 5 6 7 8 9 10 11 12 1 0 1 1 1 0 0 0 1 1 0 0
¶ 循环校验码(CRC)
循环冗余检测(Cyclic Redundancy Check,CRC)的思路是:发送消息D,它和生成多项式本质上是一致的。利用冗余位R,使得D+R凑成生成多项式的倍数,这样接收方就可以通过D+R除以生成多项式,如果余数为0,则说明没有出错,否则说明出错。
例如:
消息D为1 1 0 1 0 1 1 1 1 1
生成多项式为G为1 0 0 1 1
-
在
D后面添加G的长度减一(4)个0,得到D'。D'为1 1 0 1 0 1 1 1 1 1 0 0 0 0 -
用
D'除以G,得到余数R。做法是跑个大除法。其中我们平时除的时候用的作差换成异或。最终,得到
R为0 0 1 0 -
将
R添加到D后面,得到D+R。D+R为1 1 0 1 0 1 1 1 1 1 0 0 1 0,这就是发送的消息。

在接收端,接收到D+R后,用D+R除以G,如果余数不为0,说明出错。
对于CRC来说,如果检测到错误,那么证明一定出了错;但是如果没有检测到错误,不能证明一定没有出错。不过,只要经过严格的挑选,并使用位数足够多的除数,那么出现检测不到的差错的概率就很小很小。
同时,CRC并不能确定究竟是哪一个或哪几个比特出现了差错。一般来说,一旦检测出差错,就丢弃这个出现差错的帧。这就需要重传机制。
¶ 基本数据链路协议
先说,下面讲3个单工协议和3个双工协议(基于滑动窗口),其中前4个协议要像掌握代码一样熟悉,后两个需要知道原理,但是不必具体到代码。
基本的数据链路层协议(也就是停等协议)有三种:
-
无约束单工协议:工作在理想情况。
工作环境非常理想,几个前提:
- 单工传输
- 发送方无休止工作(要发送的信息无限多)
- 接收方无休止工作(缓冲区无限大)
- 通信线路(信道)不损坏或丢失信息帧
void sender1(void) { frame s; packet buffer; // 核心代码 while (true) { from_network_layer(&buffer); // 从网络层接收数据 s.info = buffer; // 将数据放入帧中 to_physical_layer(&s); // 将帧发送到物理层 } } void receiver1(void) { frame r; event_type event; while (true) { wait_for_event(&event); // 等待事件 from_physical_layer(&r); // 从物理层接收数据 to_network_layer(&r.info); // 将数据发送到网络层 } } -
(无错信道上的)单工停等协议:增加接收方不能无休止接收的约束,解决方案是接收方每收到一个帧后,给发送方回送一个响应。
void sender2(void) { frame s; packet buffer; event_type event; // 对于sender来说,这个事件只能是来了ACK // 核心代码 while (true) { from_network_layer(&buffer); // 从网络层接收数据 s.info = buffer; // 将数据放入帧中 to_physical_layer(&s); // 将帧发送到物理层 wait_for_event(&event); // 等待事件,所谓“停-等” } } void receiver2(void) { frame r, s; event_type event; while (true) { wait_for_event(&event); // 等待事件 from_physical_layer(&r); // 从物理层接收数据 to_network_layer(&r.info); // 将数据发送到网络层 to_physical_layer(&s); // 将dummy帧发送到物理层,用来告诉sender可以发送下一个帧了 } }所谓的dummy帧就像EVA中的Dummy Plug一样,只是用来告诉sender可以发送下一个帧了,不需要做任何事情。
-
有噪声/有错信道的单工停等协议:增加信道(线路)有差错,信息帧可能损坏或丢失的约束,解决方案是出错重传。
¶ 有错信道的单工停等协议
在该协议中,出错重传的解决方案本身带来了三个问题:
- 什么时候重传 --> 定时。
- 响应帧损坏怎么办(重复帧) --> 发送帧头中放入序号。
- 为了使帧头精简,序号取多少位 --> 1位。
发送方在发下一个帧之前等待一个肯定确认的协议叫做PAR(Positive Acknowledgement with Retransmission)或ARQ(Automatic Repeat reQuest)。
下面的描述字很多,但没有什么问题,日后可以补充一些图辅助说明:
- 该协议增加了一个计时器,发送方发出一帧,接收方只有在正确接收到数据之后才返回一个确认帧。如果到达接收方的是一个已经损坏的帧则将它丢弃,经过一段时间后发送方将超时,于是它再次发送该帧。这个过程将不断重复,直至该帧完好无损地到达接收方。
- 发送方在它所发送的每个帧的头部放上一个序号,然后,接收方可以检查它所接收到的序号,由此判断这个帧是新帧还是应该被丢弃的重复帧。
- 如果到达了一个有效确认帧,则发送方从它的网络层获取下一个数据包,并把它放入缓冲区覆盖掉原来的包,同时他还会递增帧的序号。如果到达了一个受损的确认帧,或者计时器超时,则缓冲区和序号都不作任何改变,以便重传原来的帧。
- 当一个有效帧到达接收方时,接收方首先检查它的序号,确定是否为重复数据包。如果不是,则接收该数据包并将它传递至网络层,然后生成一个确认帧。重复帧和受损帧都不会被传递给网络层,但它们的到来会导致最后一个正确接收到的数据帧的确认被重复发送,返回给发送方,以便发送方做出前进到下一帧或重发那个受损帧的决策。
先来点代码:
首先,有:
#define MAX_SEQ 1
typedef enum { frame_arrival,
cksum_err,
timeout } event_type;
这是因为我们已经约定了帧头中的序号只有一位,所以最大序号就是1。事件只可能有三种,即:
- 帧到达
- 校验和出错
- 超时
于是有sender:
void sender3(void) {
seq_nr next_frame_to_send; // 正在发送的帧的序号
frame s;
packet buffer;
event_type event;
next_frame_to_send = 0; // 初始化
from_network_layer(&buffer); // 从网络层获取初始数据
while (true) {
s.info = buffer;
s.seq = next_frame_to_send;
to_physical_layer(&s);
start_timer(s.seq); // 启动定时器
wait_for_event(&event);
if (event == frame_arrival) {
from_physical_layer(&s); // 拿ACK
if (s.ack == next_frame_to_send) { // 收到对应的ACK
stop_timer(s.ack);
from_network_layer(&buffer); // 这个“停-等”已经顺利完成,可以从网络层拿下一个数据了
inc(next_frame_to_send); // 自增帧序号
}
}
}
}
对于receiver:
void receiver3(void) {
seq_nr frame_expected;
frame r, s;
event_type event;
frame_expected = 0;
while (true) {
wait_for_event(&event);
if (event == frame_arrival) {
from_physical_layer(&r); // 拿到帧
if (r.seq == frame_expected) { // 就是你了!
to_network_layer(&r.info);
inc(frame_expected);
}
s.ack = 1 - frame_expected; // 这样可以说明ACK了哪个帧
to_physical_layer(&s);
}
}
}
这个协议能够实现重传,是因为:
- 如果拿到正确帧,相安无事
- 如果拿到校验和错误,啥也干不了,等超时
- 如果拿到超时(或者说上一种情况的超时),最终会自动超时重传
停-等协议的问题在于:只能有一个没有被ACK的帧在发送中,这样会导致发送方的带宽利用率很低。
另外提一嘴:为什么buffer不是越大越好?答案是,大buffer会带来更高的延迟。
¶ 滑动窗口协议
滑动窗口协议在基本数据链路协议的基础上,将单工通信提升到全双工通信,充分利用了通信带宽,其核心技术是捎带确认。
捎带确认(piggybacking):暂时延缓确认以便将确认信息搭载在下一个出境数据帧上的技术。
滑动窗口协议允许数据包不按次序到达,但接收机数据链路层协议将数据包递交给网络层的次序必须与发送机上数据包从网络层被传递给数据链路层的次序相同。
滑动窗口协议总共有三种,他们都能在实际(非理想)环境下正常工作,区别仅在于效率、复杂性和对缓冲区的要求,他们分别为:
- 1-bit 滑动窗口协议(发送窗口大小=1,接收窗口大小=1)
- Go Back N 协议(发送窗口大小>1,接收窗口大小=1)
- 选择重传协议(发送窗口大小>1,接收窗口大小>1)
¶ 工作原理与实现细节
滑动窗口中的窗口指的是协议关心的内容,滑动指的是关心的内容在不断变化。滑动窗口协议的实现本质上是一组针对缓冲区管理的协议。发送方和接收方都有一个(组)用于发送的和接收的缓冲区。发送缓冲区里面存放的是已经发送但没有收到确认的帧;接收缓冲区用于存放能够接收的帧。
在滑动窗口协议中,首先是对帧进行编号:发送的信息帧都有一个序号,从0到某个最大值,也就是 ~ ,一般用 n 个二进制位表示。
在发送端维护一个发送窗口:发送端始终保持一个已发送但尚未确认的帧的序号表,称为发送窗口:
- 发送窗口的上界表示要发送的下一个帧的序号,下界表示未得到确认的帧的最小编号
- 发送窗口大小 = 上界 - 下界,大小可变。
- 发送端每发送一个帧,序号取上界值,上界加1;每接收到一个正确响应帧,下界加1。
相应的,接收端有一个接收窗口:
- 大小固定,但不一定与发送窗口相同。
- 接收窗口的上界表示能够接收的序号最大的帧,下界表示希望接收的帧。
- 接收窗口容纳允许接收的信息帧,落在窗口外的帧均被丢弃。
- 序号等于下界的帧被正确接收,并产生一个响应(确认)帧,上界、下界都加1。接收窗口大小不变。
对于滑动窗口协议,有一个基本要求:数据链路层协议必须按照发送的顺序递交所有的帧。
¶ 一位滑动窗口协议
让我试图用人话来描述一下1-bit滑动窗口协议。
正是因为上面的停-等一次只发一个,确认了再下一个,所以很慢,而且信道利用率很低。1-bit滑动窗口只引入捎带ACK,所以看起来和停-等差不多。
譬如说罢,我和对方通信。此时我和对方不再像停-等一样区分sender和receiver,而是都能收发,是谓双工。对于我来说啊,我的send size是1,就是说一次发一个frame。
那么,在一切正常的情况下:
- 我要么正确发了一个帧,那么我就准备发下一个帧,同时我也准备好了接收对方的ACK。
- 要么我正确收到了响应的ACK,那么我就停了这一帧的计时器(因为没有超时嘛),准备发下一个。
看起来和停-等很像,唯一区别在于发的帧捎带了ACK,和停-等相比,看起来就好像没有发ACK一样,所以效率更高。
现在我们考虑出错的情况,如果checksum出错,那么我就不管了,等超时重发就好了。如果我收到了一个ACK,但是ACK的序号不对,那么我也不管,等超时重发就好了。总之就是,不是我要的就全让他们timeout就行了。我只在正确响应ACK时才停掉计时器。
来点代码:
#define MAX_SEQ 1
typedef enum { frame_arrival,
cksum_err,
timeout } event_type;
首先这里是不变的,因为1-bit所以MAX_SEQ是1(多离谱啊),事件也还是老三样。
然后:
void protocol4(void) {
// 此乃双工协议,一个函数,同时收发
seq_nr next_frame_to_send; // 下一个发送的帧
seq_nr frame_expected; // 下一个期望收到的帧,这俩在这个协议中都是要么0要么1
frame r, s;
packet buffer;
event_type event;
next_frame_to_send = 0;
frame_expected = 0; // 这俩都是初始化
from_network_layer(&buffer); // 从网络层取数据
s.info = buffer; // 准备发第一帧
s.seq = next_frame_to_send; // 发送的帧号
s.ack = 1 - frame_expected; // 捎带ACK
to_physical_layer(&s); // 发送第一帧
start_timer(s.seq); // 开始计时
while (true) {
wait_for_event(&event);
if (event == frame_arrival) {
from_physical_layer(&r);
if (r.seq == frame_expected) {
to_network_layer(&r.info);
inc(frame_expected); // 期望收到的帧号自增(虽然实际上是反转但是反正意思到了)
}
if (r.ack == next_frame_to_send) {
stop_timer(r.ack); // 停止计时
from_network_layer(&buffer);
inc(next_frame_to_send);
}
s.info = buffer;
s.seq = next_frame_to_send;
s.ack = 1 - frame_expected;
to_physical_layer(&s);
start_timer(s.seq);
}
}
}
¶ 回退N协议

注意,下图中NAK 2后的多个ACK 1,这个就是“累积确认”法。直到ACK 2到了,那么Frame 1, 2, 3, 4, 5都到了,可以发ACK 5。
参考视频:https://www.bilibili.com/video/BV1fU4y1h7Sw
直接静音三倍速速通就行了
来说点人话。譬如说罢,我有个window size为4的发送窗口。为了进一步提高信道的利用率,我直接全发了;我要是接收到了什么frame,如果正确就也把ACK带上。
这种情况下,对面收我的frames。倘若一切OK,那么我把窗口里的帧全发了以后,过一段时间就会有一系列带着正确ACK的响应回来。如果有问题(不管是超时还是checksum出错),那么,我这里第一个有问题的ACK在哪,我就要从那一帧开始重发,不论后面的帧发的多么正确。
例如,我如果扔了个A B C D出去,过段时间回了带有正确ACK的,那什么都好说;如果我拿到的ACK,A,B与D正确,但C有问题,那我要从C开始重发,D就算白发了,也要重新来。
本质上,这意味着接收窗口的window size是1。
¶ 选择性重传协议
显然,Go Back N协议的缺点在于,如果有一个帧出错,那么后面的帧即使正确也要重发。
因此一个改进的措施就是只重发出错的帧,这就是选择性重传协议。为了实现这一点,改进的本质是增大了接收窗口的大小,使得接收方可以缓存多个帧。比如,让发送窗口的大小和接收窗口大小一致。一般来说,这个尺寸是。
一切如常的情况和上面一样,就不说了;如果出错,后面的帧该ACK还是ACK,直到出错帧timeout,sender重传这单个帧。
关键在于,只要窗口在,怎么接收都可以。但是出错帧会导致窗口不能向后滑动,窗口后面正确发的帧会被缓存。
¶ 介质访问控制子层
¶ 概述
Medium Access Control,MAC 子层还是属于数据链路层,是它的一个子层,实际上是整个数据链路层的底层。
在同一介质中相同频率波段的传输信号会相互干扰,导致无法得到有效的信号,而采用频率,时间区别不同信号又无法最大限度地利用资源,这时候就希望有种协议可以协商三个以上的机器如何可以在没有统一调度的前提下“遵守秩序”、“不打断别人”地发言,让介质顺利被利用不产生冲突。
所以说,根本上讲,介质访问控制(MAC)是当多个使用者共享同一个信道时,确定下一个使用者的问题。
¶ 多路复用
多路复用:多个信号组合起来在一条物理信道上进行传输的方式。多路复用可以提高对带宽的利用率,其方法主要有三种:
- 频分多路复用(FDM)
- 时分多路复用(TDM)
- 波分多路复用(WDM)
静态 FDM 性能差,因为它会 N 倍放大延迟,即:。其中 是 FDM 之前原本的平均延迟。显然,这一切对于 TDM 也是一样的。
¶ 基本假设
首先,静态信道假设(FDM,TDM)方式不适用于突发流量,需要动态分配信道的协议实现。动态信道分配问题的假设如下:
- 流量独立:每个站独立产生流量。
- 单信道假设:所有站共享同一信道。
- 冲突假设:如果两帧“同时传输”(传输时间有重叠),会产生信号重叠造成信号混乱、不可识别,称为“冲突”。冲突使所有传输失败。
- 时间连续或分槽(离散):如果时间连续,则在任何时刻可以开始传输数据;如果时间离散, 则只能在某个时间槽的起始点开始传输。
- 载波侦听或不侦听:侦听判断当前信道是否空闲。
¶ 基本思路
介质访问控制问题的基本解决思路可以分为两种:基于冲突的和无冲突的解决方案,还有一种混杂协议结合这两种方案特点的有限竞争协议。
无冲突的解决方案各站点遵守事先确定的竞争规则,合理安排各个站发送数据的顺序,不会产生冲突。包括以下几个协议:
- 基本位图法:在一个竞争周期内,如果某个站有数据发送,则当其对应的时槽到来时置1,错过则等待下一个竞争周期。竞争周期结束后,时槽置1的站轮流发送数据。需要事先安排各个站的编号及对应的竞争时槽。
- 令牌传递:所有站组成一个逻辑环,令牌按照某种方向在逻辑环上传递。获得令牌的站拥有发送数据的权力。发送完毕后,将令牌向后传递到下一个站。需要事先安排逻辑环上各个站的顺序。
- 二进制倒计数:每个站拥有一个逻辑地址,发送时各个站按位从高到低广播自己的逻辑地址。信道将所有地址位布尔或在一起。每个站将自己的地址位与布尔或后的位比较,自己地址位小的竞争失败并放弃发送后续的地址位。最终剩余的站竞争成功并随后发送数据。需要事先安排站的逻辑地址。
基于冲突的解决方案没有事先约定的竞争顺序,各个站公平地竞争信道。此时,冲突不可避免,协议基于冲突解决各个站的发送顺序。
有限竞争协议综合以上两种协议特点,将所有站分成若干个组,组内公平竞争(基于冲突),组间按照一定顺序竞争(无冲突)。
无线局域网拥有不同于有线局域网的特点,冲突检测困难,信道侦听复杂,采用了类似于经典以太网但冲突避免的协议。
因此,基于冲突的协议和无线局域网都需要处理竞争问题,基于竞争解决MAC问题的几个关键思想如下:
- 时间离散化。
- 随机发送。
- 载波侦听(不打扰已有通信)。
- 失败重传(基于冲突检测或确认是否回来)。
这部分的实践是基本一致的,无论是经典以太网还是无线局域网。这样的网络里都可能有多个站点有数据发送,此时:每个站点随机选择发送时间以尽最大可能避免冲突,使得某个站点在所选时刻以较大概率独自发送(竞争成功);其它站点能够感知这个发送不再干扰(通过载波侦听);冲突后重传。
但是:
- 经典以太网比较容易检测冲突,所以采用较为激进的1-坚持CSMA,冲突后使用2进制指数后退算法分解冲突。
- 无线局域网难于检测冲突,直接采用冲突避免的改进的p-坚持CSMA分解冲突。
- 交换式局域网采用缓存与合适的调度算法分解冲突。
¶ 多路访问协议
这里的多路访问协议主要指经典以太网中的多路访问协议,无线局域网中略有差异。
经典以太网是最重要的一种局域网模式,所有站点共享同一个传输介质(信道),采用基带信号,采用广播传输技术,因此需要多路访问协议以实现对信道的利用。即每个站将自己发送的数据通过收发器发送到传输介质上,信号占用信道所有带宽,信号沿传输介质传递到每个站点。当两个或多个站同时传输信号,则会发生信号叠加,造成接收方接收失败,所有传输都会失败。
经典以太网每个时刻只允许一个站点发送数据。没有事先规定的竞争顺序,允许竞争时产生冲突,并基于冲突解决介质访问控制问题。在经典以太网的竞争和冲突解决发展过程中,存在五个阶段:
- 想说就说——ALOHA
- 先听后说——CSMA
- 边说边听——CSMA/CD
- 二进制指数后退
- 最小帧长
¶ ALOHA协议
按照对时间管理的不同,分为连续时间和离散时间,对应的协议分别为:纯ALOHA,分槽ALOHA。
- 纯ALOHA协议:当站点有数据要发送时就发送。如果多个用户同时发送则会发生冲突造成发送失败。发送失败后(发送站会依靠某种方法得知),等待一段随机时间再次发送。等待一段随机时间为了有效解决冲突。
- 分槽ALOHA协议:是纯ALOHA协议的改进。将时间离散化,分为时间槽(一段事先规定的时间)。只有在时间槽的起始点可以发送。通过推迟发送时间,避免连续时间发送带来的某些冲突。
纯ALOHA协议可以在低负载下获得较高的效率和较低的延迟,其工作示意图如下所示:
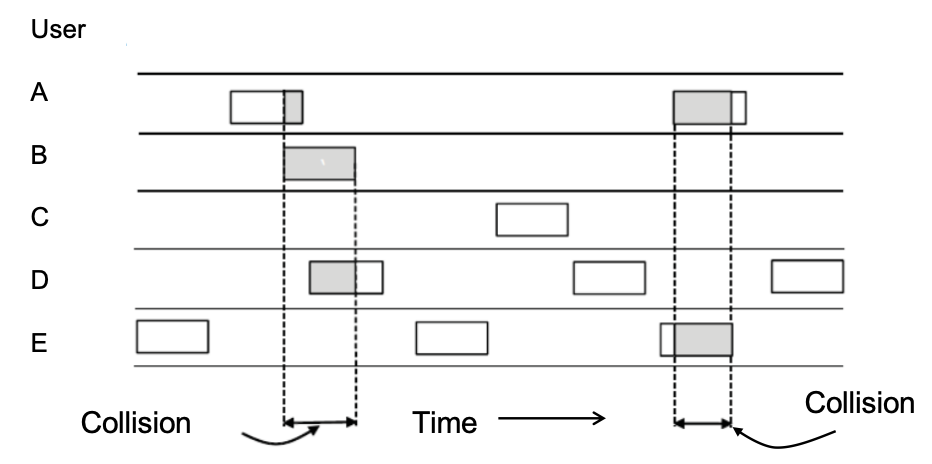
进一步讲,纯ALOHA的系统吞吐量,其中是系统负载,也就是平均下来每帧时内产生的帧数;是每帧时内成功传输的帧数。显然,首先就有。

在时,函数取到极值,反正不到的。
Slotted ALOHA 就不一样了,吞吐量。分槽使得碰撞危险减少了一半。

极值点在处,到了不到的水平。

总的来说,就酱。
¶ CSMA
为了不打扰已有的通信,站点在发送数据之前首先侦听信道。如果信道空闲,则发送;如果信道忙,代表有其它站点在发送数据,则不能发送,等待一段随机时间发送。
这种发送数据之前先侦听信道是否空闲的协议称为载波侦听多路访问协议(CSMA,Carrier Sense Multiple Access)。根据贪婪程度和处理策略不同,分为:
-
1-坚持CSMA:站点在发送数据之前首先侦听信道。如果信道空闲,则发送;如果信道忙,则继续侦听,直到信道空闲,立即发送。避免打扰已有的通信,但是不能完全避免冲突。
可能的冲突情况:假如现在站点A正在发送数据,站点B想要发送数据,先侦听信道,信道忙,则站点B持续侦听信道。接着(或“同时”)站点C也有数据要发送,执行同样的协议。当站点A发送完毕后,站点B和C都侦听到信道空闲,都会选择立即发送。结果,站点B和C发送数据冲突,都会发送失败。
1-坚持CSMA只是将连续时间上的冲突压缩到前一个数据传递完毕(一个时刻)。
-
非坚持CSMA:站点在发送数据之前首先侦听信道。如果信道空闲,则发送;如果信道忙,则等待一段随机时间再来侦听。能够有效避免1-坚持CSMA协议不能真正分解冲突的问题。
非坚持CSMA协议在提高整个系统吞吐量(系统在单位时间内能够真正完成的数据传输次数)的同时,可能会带来较大的延迟(对每一次数据传输而言)。
-
p-坚持CSMA:适用于时间分槽系统。站点在发送数据之前首先侦听信道。如果信道空闲,则以概率发送数据;以概率推迟到下一个时槽;重复以上过程,直到发送出去或听到信道忙。如果信道忙,则等待一段随机时间再来重复以上协议。
p-坚持CSMA协议可以有效分解潜在的可能的冲突。由于每个站点都运行这个协议,选择了不同的发送时间槽,两个或多个站同时选择一个时间槽的概率随着的变小而降低。可以提高吞吐量,但可能带来更大的延迟。

显然,当p-坚持的概率趋近于1时,p-坚持CSMA协议的性能趋近于1-坚持CSMA协议;当趋近于0时,自然在吞吐量较大时能避免冲突(因为试图在发数据的很多,但是发出来的概率比较低,所以冲突少),但是缺点是会带来较大的延迟。
¶ CSMA/CD
先听后说(CSMA)协议要求所有有数据发送的站点侦听到信道空闲时才能发送数据,从而不会打扰已有的通信过程,但是不能完全避免冲突(不能保证站点发送一定成功,或成功获得信道的使用权),尤其是当多个站点同时侦听到信道空闲。
当两个帧发生冲突时,两个被损坏帧继续传送毫无意义,而且信道无法被其他站点使用,对于有限的信道来讲,这是很大的浪费。如果站点边发送边监听,并在监听到冲突之后立即停止发送,并立即进入竞争周期,尽快得到竞争解决方案,可以提高信道的利用率,因此产生了CSMA/CD。
实现机制:
- 发送方一边向信道发送(说)数据,一边从信道上读取(听)数据,通过判断双方是否一致来判断是否发生了冲突。
- 所有站点还要同时运行冲突检测(CD, Collision Detection)协议,边发送数据(竞争信号)边检测信道上是否发生了冲突。如果听到冲突,则表明还有其它站点“同时”发送数据,代表本次发送失败(所有发送站点都会意识到这一点)。听到冲突的站点立即停止发送(提高效率),运行BEB协议分解冲突。
- 如果站点在发送过程中没有听到冲突,则认为本次发送成功(或取得总线的控制权)。
¶ 二进制指数后退
BEB算法(Binary Exponential
Backoff Algorithm)方案描述如下:
- 站点运行CSMA/CD协议,听到冲突后进入竞争周期,时间离散为多个时间槽。
- 如果第一次冲突,则参与竞争的站点在随后的两个时间槽内随机选择一个发送,发送前依然要侦听信道是否空闲。
- 排在最前面的只有一个竞争者的时间槽对应的竞争者竞争成功,随后抓住信道发送数据,其它竞争者等到选择的竞争时间槽时侦听信道为忙,只能等待已有通信完成再次尝试发送。
- 当一个时间槽有两个竞争者就都会听到冲突,全部竞争失败。竞争失败的站点将随机等待的时间槽数加倍,然后从中随机选择一个参与竞争,直到竞争成功或达到最大竞争次数。
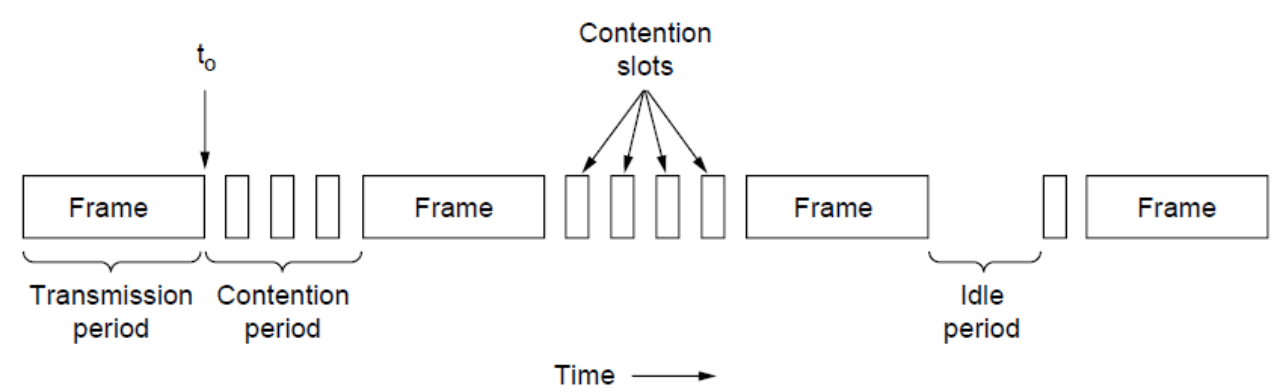
- 二进制指数后退指的是每次冲突后随即后退的时间槽翻倍,直到1024个时间槽(即10次冲突)。如果在1024个时间槽运行6次(也就是总计16次尝试)依然解决不了冲突,则认为网络坏了。
- 竞争周期时间槽的时间应该远远小于普通帧长。这样能够减少冲突带来的消耗,提高信道使用效率。
- 对每一个站点,选择任何一个时间槽都是公平的。因为一个时间槽的好坏不只是取决于是否靠前,更重要的是是否其它竞争者也选择了这个时间槽(博弈论)。
- 竞争周期的最后结果是某一个站点获得信道使用权。
¶ 最小帧长
最小帧:为了确保发送站在发送数据的同时能够检测到可能存在的冲突,需要在发送完帧之前就收到自己发送出去的数据。
最小帧长:发送方必须发送的最小时间,对应着必须发送的最少数据。凡是小于最小帧长的帧就把它当做无效帧丢弃。
以太网(802.3)规定了最小帧长为 64 字节(64 bytes or 512 bits ),凡长度小于 64 字节的帧都是由于冲突而异常中止的无效帧。
一个站点执行 CSMA/CD 协议,当发送(竞争)过程中没有听到冲突,则认为发送(竞争)成功。然而,考虑到信道传输延迟时,这个结论需要前提条件保证才是正确的,那就是:发送方必须发送足够长时间的数据,才能够检测到发生在“远方”的冲突,从而做出正确的判断。
这其实是说,计算机网络系统本质是一个分布式系统,每个站点只能依据自己周围的是否有信号叠加( “局部信息” )来推断整个信道上是否有冲突( “全局结论” ),或依据自己周围是否空闲来推断整个信道是否空闲。
最小帧长 = 总线传输时延 数据传输速率 2 = 2 以太网的速度。
原理图:

其实就是说,最先发送数据帧的站,在发送数据帧后至多经过时间(两倍的端到端往返时延),就可知道发送的数据帧是否遭受了碰撞。故,将称为争用期或碰撞窗口。经过争用期这段时间还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
例题:假设一个采用 CSMA/CD 的 100 Mbps 局域网,最小帧长是 128B,则在一个冲突域中两个站点间的单程传输延时最多是?
- A. 2.56
- B. 5.12
- C. 10.24
- D. 20.48
解:,而,解得。当然,两个站点间的单程传输延时最多是,也就是。
¶ 交换以太网
交换以太网是以交换机为核心设备而建立起来的一种高速网络,可在高速与低速网络间转换,实现不同网络的协同。交换机分割了连接的不同网络成为不同的冲突域,不同冲突域之间信号不会彼此干扰,所以不用考虑不同自治域间的冲突问题。
经典以太网中,随着网络规模不断扩大,依然是一个CSMA冲突域。即每个时间只能够有一个站点发送数据,介质利用率低,每个站点的平均使用带宽下降。
其解决思路就是同时支持尽可能多的通信,将一个冲突域划分为多个冲突域(网络微分段)。
使用的网络设备为网桥或交换机。网桥(交换机)的功能是将连接的网段断开,需要时连接(桥、桥接)。这样,发生在一个网段的通信信号不会“自动”(像中继器、集线器那样)转发到另外的网段。网桥/交换机使用缓存和调度避免冲突、实现转发桥接功能。
¶ 以太网
这里很奇怪,复习考点是如此编写的,但是就是很怪,建议仅了解以太网帧就好,考试的时候也会给出帧结构的。
¶ 帧格式

两种以太网 MAC 帧格式标准:
- DIX Ethernet V2
- IEEE 802.3
一般而言以前者为常用标准。
| Structure | 结构 | 长度 |
|---|---|---|
| DA, Destination Address | 目标地址 | 6B |
| SA, Source Address | 目标地址 | 6B |
| Type | 类型 | 2B |
| Data | 数据(其实就是IP数据报) | 0~1500B |
| Pad | 间隔(用来保证合法地满足最小帧长) | 0~46B |
| Checksum | 校验码 | 4B |
有的时候把Data和Pad合计为Data字段,长度至少为46B;另外,值得注意的是,DA与SA都是6B,这实际上也印证了MAC地址的长度。
MAC帧无效的情况:
- 数据字段的长度与长度字段的值不一致
- 帧的长度不是整数个字节
- 用收到的帧检验序列 FCS 查出有差错
- 数据字段的长度不在 46 ~ 1500 字节之间
对于检查出的无效 MAC 帧就简单地丢弃。以太网不负责重传丢弃的帧。
¶ 曼彻斯特编码
前面说过了,导播切台!(雾
¶ LLC
很可能不考。混个眼熟吧。
LLC(Logical Link Control)逻辑链路控制,是OSI参考模型中的第二层,也就是数据链路层的上半部分,主要负责数据链路层的逻辑链路控制,即逻辑链路的建立、维护和释放。
不过一般不考虑 LLC 子层,因为TCP/IP 体系经常使用的局域网是 DIXEthernet V2 而不是 802.3 标准中的几种局域网,因此现在 802 委员会制定的逻辑链路控制子层 LLC(即 802.2 标准)的作用已经不大了。
¶ 无线局域网
无线局域网只使用一个信道,支持广播传输模,形式上类似于经典以太网。
无线局域网与有线局域网的不同:
- 两者的传输介质有着本质区别,也正是这种区别,导致WLAN存在新的问题:隐藏终端问题和暴露终端问题。
- 两者传输范围有区别:WLAN 中,无线电传输范围有限,一个站不能给所有其他站发送帧,也无法接收来自所有其他站的帧;在有线局域网中一个站发出一帧,所有其他站都能接收到。
- 信道检测方式不同:WLAN采用能量检测、载波检测和能量载波混合检测三种检测信道空闲的方式;以太网通过电缆中电压的变化来检测。
- 在 WLAN 中,对某个节点来说,其刚刚发出的信号强度要远高于来自其他节点的信号强度,也就是说它自己的信号会把其他的信号给覆盖掉,但在本节点处有冲突并不意味着在接收节点处就有冲突。
¶ MACA
MACA(Multiple Access with Collision Avoidance protocol)的工作方式基本是这个样子:
- 发送方刺激一下接收方(RTS帧),让他输出一个短帧(CTS帧),因此接收方附近的站可以检测到该帧,从而在接下去的数据帧(较大)传输过程中他们不再发送数据了。
- 发送方发送RTS(request to send)帧,这个短帧包含了随后要发送的数据帧的长度,接收方用CTS(Clear to send)作为应答,此CTS也包含了数据长度。
- A在接收到了CTS后开始传输。
在WLAN中,存在隐藏终端和暴露终端两个基本的问题:
隐藏终端问题:无法感知彼此的发送者,但仍会在预定的接收方发生碰撞。如下图所示:
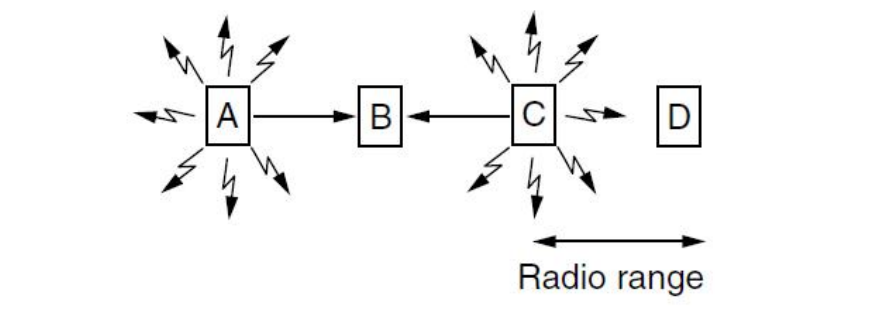
例如,A 给 B 发,但 C 的信号接收覆盖范围没法覆盖到 A,导致不知道A在给B发,误以为B 空闲,一旦发送,则信号会冲突干扰,导致失效。
可以看到,问题的关键在于 C 无法知道 B 的接收情况,因为之前的监听是在发送方C自己这里进行的,这个问题是致命的。
暴露终端问题:可以相互感知但仍然安全地传输(到不同的接受者)的发送者。
例如,B给A发,此时 C 想要发送信号给D,但C监听到介质上有信号传输,则会等待B 传输结束再进行给 D 的传输,但实际上这种等待是不必要的。
C 即使发给 D 也不会干扰 A 的接收信号,因为干扰只在接收方端产生,所以这种问题带来了效率的降低,根源还是在于 C 不知道接收方A的情况,只知道自己附近发送方B的情况。但注意并不是致命的,因为还是没有破坏传输。
为了解决这两个问题,即之前的 CSMA 只能监听到发送方附近而不是接收方附近介质情况根本问题,希望能通过协议让接收方也“发言”,即通过这次信号让接收方附近的站点也能感受到接收方的存在,从而避免后续的继续发送造成该接收方的冲突。
解决的方案就是发送方先发 RTS(Request To Send),之后接收方回CTS(Clear To Send)信号,并从这个信号中包含这次传输的持续时长信息,保证让此时长内接收方附近站点主动静默,从而不会使其受到干扰。如下图所示:
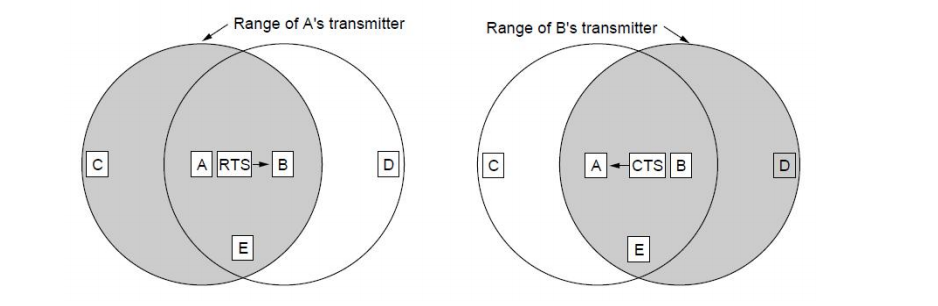
- 一个点如果只听到 RTS,没有听到CTS,说明它在发送方的发送范围内,却不在接收方的发送范围内,则它只要不干扰发送方收CTS,即可随便发送。解决了暴露终端问题。
- 一个点如果只要听到CTS说明它就在接收方发送范围内,此时它要保持静默到持续时长,直到此次传输结束它再进行发送,否则会干扰接收方接收。解决了隐藏终端问题。
MACAW 是为了解决如果没有数据链路层的确认,则传输层注意到丢帧之前,这些丢失的帧不会被重传,而到那时候已经太晚了,所以:
- 在每个成功的数据帧之后引入一个ACK帧。
- 载波检测被加入进来,因为当附近的一个站正在给某一个目标站发送RTS时,可以避免当前的站也给同一个目标站发送RTS帧。
- 为每一个单独的数据流(即源-目标对),而不是每一个站运行后退算法。
- 还增加了一种供各个站之间交换有关拥塞信息的机制。
¶ 802.11MAC子层协议
802.11在MAC子层的协议上有两种:
- DCF(Distributed Coordination Function)
- PCF(Point Coordination Function)
其中,前者是802.11标准中最基本的媒体访问控制(MAC)协议,也是默认的MAC协议;后者则提供了一种基于集中式调度的媒体访问控制方式,它允许一个特定的节点作为主节点(Point Coordinator)来控制整个网络的访问。
在 DCF 中,节点通过监听信道来检测是否有其他节点正在发送数据。如果信道空闲,节点可以开始发送数据。如果信道被占用,节点将等待一段随机的时间(退避时间),然后再次尝试发送。这种退避机制有助于避免碰撞,并提供了一种分布式的协调方式。
在 PCF 中,主节点负责调度节点的访问。它周期性地发送一个帧,称为 Beacon 帧,来通知其他节点网络的存在和 PCF 的可用性。主节点根据一定的调度算法,分配时间片给各个节点,使它们可以按照指定的时间间隔发送数据。
CSMA/CA(CSMA with Collision Avoidance)是带有冲突避免的CSMA协议。它是802.11 MAC子层协议的核心协议,实现了 DCF。与之前的 MACA 相比,它引入了短确认确保每一帧的发送成功,即数据发送后站点启动确认计时器,如果计时器时间到但没有收到接收方回复的收到的确认,则试图重新发送。但它在RTS 和 CTS 方面并没有考虑暴露终端问题。
CSMA/CA有两种工作模式:
模式一:感测信道,如果空闲,则开始传输。如果发生冲突,则等待随机时间,使用以太网二进制指数退避算法;
模式二:基于MACAW,使用虚拟信道感知。例如,A 想要给 B 发送数据,C 在 A 的发送范围内,而 D 在 B 的发送范围内,但不在 A 的发送范围内。A 发送 RTS 给 B,B 发送 CTS;A 开始发送数据,并且启动 ACK 计时器。此时,C 会收到 RTS,D 会收到 CTS,这就用上了 NAV(Network Allocation Vector)。
RTS与CTS:与MACA 类似,但是将规则改成了听到 RTS 后也停止传输一切东西,直到此次数据传输结束后再进行传输。这样其实是无法解决暴露终端问题的,但由于考虑到暴露终端问题是效率问题而不是致命问题,且处理这个不经常发生的问题需要耗费操作时间,所以就进行了舍弃。
网络分配向量(NAV,Network Allocation Vector):每格站点保留的信道何时要用的逻辑记录,每个帧携带一个 NAV 字段,说明这个帧所属的一系列数据将传输多长时间。所有听到数据帧的站将在发送确认期间推迟发送,不管能否真正听到确认的发送。
二进制指数后退的CSMA/CA:侦听很短的一段时间后发现没有信号,则随机选择 0-15 个时间槽进行倒计时倒数,当听到有帧发送时暂停倒计时,空闲时计数,到0时就发送,如果发送成功则目标站会发送一个短确认,如果没收到确认,则发送方加倍自己选择的时间槽数,重新试图发送。如此反复, 直到成功发送帧或达到最大重传次数。
关于802.11的帧结构,我觉得了解即可。
| Structure | 结构 | 长度 |
|---|---|---|
| Frame Control | 帧控制 | 2B |
| Duration | 持续时间 | 2B |
| Address 1 (recipient) | 接收者地址 | 6B |
| Address 2 (transmitter) | 发送者地址 | 6B |
| Address 3 | 中间节点地址 | 6B |
| Sequence | 序列号 | 2B |
| Data | 数据 | 0~2312B |
| Check sequence | 校验序列 | 4B |
其中:
-
Frame Control(帧控制):帧控制字段是802.11帧的第一个字段,用于指示帧的类型和子类型,以及其他控制信息。它包含了帧的版本、类型、子类型、帧的传输方式、帧的加密状态等信息。
-
Duration(持续时间):持续时间字段指示了发送方在信道上保持占用的时间,以便其他节点知道何时可以访问信道。这个字段的长度根据具体的物理层速率而定。
-
Address 1:地址1字段是目的地址,用于指示帧的接收方。它可以是单播地址(指定一个特定的接收节点)、广播地址(指定所有节点)或组播地址(指定一组节点)。
-
Address 2:地址2字段是源地址,用于指示帧的发送方。
-
Address 3:地址3字段是用于指示帧的中间节点的地址,例如在无线分布式系统中的中继节点。
-
Seq.(序列号):序列号字段用于指示帧的顺序,以便接收方可以正确地重新组装数据帧。每个数据帧都有一个唯一的序列号。
-
Data(数据):数据字段包含实际的数据,可以是网络层的数据包、控制信息等。数据字段的长度可以根据具体的需求和帧类型而变化。
-
Check sequence(校验和):校验和字段用于检测帧在传输过程中是否发生了错误。发送方在发送帧之前计算校验和,并将其添加到帧中。接收方在接收帧后再次计算校验和,并与接收到的校验和进行比较,以检测错误的存在。
Frame Control(帧控制)字段详细内容如下:
-
Version(版本):2 bits. 版本字段指示了帧的版本号,用于标识所使用的802.11协议的版本。不同的版本可能支持不同的功能和扩展。
-
Type(类型):2 bits. 类型字段指示了帧的类型,用于区分不同类型的帧。常见的帧类型包括管理帧(Management Frame)、控制帧(Control Frame)和数据帧(Data Frame)。
-
Subtype(子类型):4 bits. 子类型字段进一步细分了帧的类型,用于指示帧的具体子类型。例如,对于数据帧,子类型字段可以指示数据帧是普通数据帧、分片数据帧等。
-
To DS(目标到发送者方向):1 bit. To DS字段用于指示帧的传输方向。当该字段设置为1时,表示帧的目标是发送者(即,从无线接入点发送到无线客户端);当该字段设置为0时,表示帧的目标是接收者(即,从无线客户端发送到无线接入点)。
-
From DS(发送者到目标方向):1 bit. From DS字段与To DS字段相反,用于指示帧的传输方向。当该字段设置为1时,表示帧的源是发送者(即,从无线客户端发送到无线接入点);当该字段设置为0时,表示帧的源是接收者(即,从无线接入点发送到无线客户端)。
-
More frag.(更多分片):1 bit. More frag.字段用于指示是否还有更多的分片数据帧。当该字段设置为1时,表示还有更多的分片数据帧;当该字段设置为0时,表示这是最后一个分片数据帧。
-
Retry(重试):1 bit. Retry字段用于指示帧是否是重试的帧。当该字段设置为1时,表示这是一个重试的帧;当该字段设置为0时,表示这不是一个重试的帧。
-
Pwr. Mgt.(电源管理):1 bit. Pwr. Mgt.字段用于指示帧的电源管理状态。当该字段设置为1时,表示接收方可以进入低功耗模式;当该字段设置为0时,表示接收方需要保持活动状态。
-
More data(更多数据):1 bit. More data字段用于指示是否还有更多的数据帧等待接收方处理。当该字段设置为1时,表示还有更多的数据帧等待处理;当该字段设置为0时,表示没有更多的数据帧等待处理。
-
Protected(保护):1 bit. Protected字段用于指示帧是否进行了加密保护。当该字段设置为1时,表示帧已经进行了加密;当该字段设置为0时,表示帧没有进行加密。
-
Order(排序):1 bit. Order字段用于指示数据帧是否需要按照顺序传输。当该字段设置为1时,表示数据帧需要按照顺序传输;当该字段设置为0时,表示数据帧的传输顺序可以不按照顺序。
¶ 数据链路层交换
¶ 网桥/交换机
网桥(bridge)是工作在数据链路层的一种网络互连设备,它在互连的LAN之间实现帧的存储和转发。网桥本身具有中继器的功能,只是在此之上添加了新的功能。
网桥的工作过程如下:
- 当一帧到达时,网桥必须决定是将该帧转发还是丢弃
- 如果决定转发,还必须要决定在哪个端口传输帧
- 网桥通过在其内部配备一个大的(哈希)表来查询一帧的目的地址,该表中列出了每一个可能的目的地址以及它隶属的输出端口
- 当网桥第一次被接入网络时,所有的哈希表都是空的,网桥使用洪泛算法完善哈希表。
- 其具体转发过程为:
- 目的地址的端口与源端口相同,则丢弃该帧
- 目的地址的端口与源端口不同,则转发该帧到目的端口
- 目标地址端口未知,则使用洪泛算法,将帧发送到所有的端口,除了他入境的那个。
泛洪算法:不需要知道网络的拓扑结构和相关的路由计算,仅要求接收到信息的节点以广播的形式转发数据包。对于每个发向未知目的地址的入境帧,网桥将他输送到所有的端口,除了它到来的那个端口,慢慢的网桥学习到目标地址在哪里)和向后学习法(通过检查每个窗口上发送的所有帧的源地址,网桥就可获知通过那个窗口能访问到哪些机器。
网桥(交换机)的交换功能主要由三个模块组成:转发模块、自学习模块和MAC-端口映射表(也称MAC地址表)。
转发模块依据映射表决定入境的帧应该从哪个端口转出。转发规则为:
- 当发送方和接收方在同一个端口,则不转发;
- 否则,如果查找映射表成功,按照映射表转发;
- 否则,向其余全部端口转发。
自学习模块主要负责“实时”(可能几分钟)地将网络拓扑(主要指站点和端口的连接关系)的情况和MAC-端口映射表同步。简单说,让映射表能够动态反应网络拓扑的变化。
- 自学习模块采用后向(逆)学习机制:当收到一个入境帧时,将其内部携带的“源地址”与进入端口的关联关系写入映射表中。
- 自学习模块是一种动态学习机制:映射表是动态建立的,能够动态反应网络拓扑。开始时为空,随着流量的增多,映射表不断完善。
- 映射表中每个表项关联一个计时器,在规定时间内没有刷新的表项会被删除。
MAC-端口映射表(MAC地址表)记录目的地址(物理地址)对应的端口号和更新时间。
¶ 生成树网桥
生成树网桥:最低标识符(基于MAC地址)的网桥作为生成树的根。
为了提高可靠性,有人在LAN之间设置了并行的两个或多个网桥,但是,这种配置引起了另外一些问题,因为在拓扑结构中产生了回路,可能引发无限循环。
解决上面所说的无限循环问题的方法是让网桥相互通信,并用一棵到达每个LAN的生成树覆盖实际的拓扑结构。使用生成树,可以确保任两个LAN之间只有唯一一条路径。一旦网桥商定好生成树,LAN间的所有传送都遵从此生成树。由于从每个源到每个目的地只有唯一的路径,故不可能再有循环。
为了建造生成树,首先必须选出一个网桥作为生成树的根。实现的方法是每个网桥广播其序列号(该序列号由厂家设置并保证全球唯一),选序列号最小的网桥作为根。(经过足够的消息交换和扩散)接着,按根到每个网桥的最短路径来构造生成树。结果,从每个LAN到根建立了一条唯一的路径,因而从每一个LAN到其他任何一个LAN也建立了一条唯一的路径。如果某个网桥或LAN故障,则重新计算。
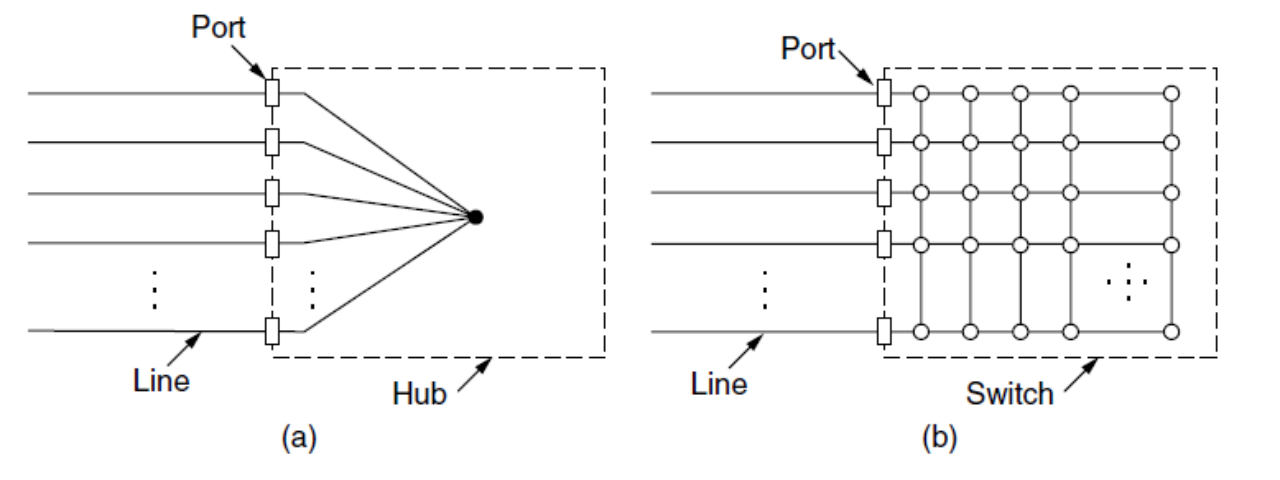
¶ 各种网络设备
- 中继器:物理层,模拟设备,用于连接两根电缆段,放大信号。
- 集线器:物理层,有许多输入线路,它将这些输入线路连接起来,在任何一条线路上到达的帧都被发送到其他线路上。
- 交换机:数据链路层,多端口的网桥。根据帧的目的地址转发,常被用来连接独立计算机。
- 路由器:网络层,当一个分组进入到一个路由器中的时候,帧头和帧尾被剥掉,位于帧的 IP 分组被传递给路由软件,路由软件利用分组的头信息来选择一条输出线路。
- 网关:传输层,应用层。应用网关是将一个网络与另一个网络进行相互连通,提供特定应用的网际间设备,应用网关必须能实现相应的应用协议。应用网关可设在应用层或传输层。设在应用层的叫应用层网关,也称代理服务器。设在传输层的叫传输层网关。
网桥和路由器的主要区别:
-
网桥只能连接两个逻辑相同的网络(它相当于一个二层交换机),而路由器可以连接不同网络;网桥就是把不同物理位置的机器组成一个大的局域网,连接的多个网络属于同一个局域网;网桥连接的两个网络在逻辑上属于同一个局域网,但可以是不同策略的网络,如以太网和令牌环网;路由器可以连接不同的网络,连接的网络之间可以说没什么关系,是独立的。
-
网桥基于 MAC 地址转发,路由器基于 IP 转发。
-
网桥不隔离广播,而路由器可以隔离广播。
-
网桥工作在链路层,路由器工作在网络层。
¶ 网络层
¶ 概述
数据链路层保证了数据在相邻节点的可靠传输,网络层关注的是如何将源端数据包经过网络上的节点一路送到接收方。为了实现这个目标,网络层必须知道网络拓扑结构,并从中选出适当的路径。
网络层的功能通过网络层设备路由器实现。路由器是网络层设备,除了具有网络层的功能以外,还具有物理层和数据链路层的功能。
当一个IP分组到达路由器其主要的转发过程:
- 当有一个IP分组到达路由器,进入等待队列,通过某种调度方式进行调度。
- 调度到这个消息时,取出其目的地址,并将其与路由表中所有的网络号的子网掩码进行匹配,选取最长匹配的地址进行转发。
- 如果没有匹配的表项,发送到缺省表项继续转发。
存储转发:将入境数据缓存(存储),根据一定的规则调度到出境端口并发送(转发)的过程。
网络层向传输层提供的服务包括无连接的服务和面向连接的服务:
他俩其实就是对应前面PSTN的交换技术。
- 数据报子网:使用无连接的服务,所有的数据包都独立地注入到网络中,并且每个数据包独立路由,不需要提前建立任何设置。数据包通常成为数据报,对应的网络成为数据报网络。
- (虚)电路子网:使用面向连接的服务,在发送数据包之前,必须先建立起一条从源路由器到目标路由器之间的路径,这个连接成为虚电路,对应的网络成为虚电路网络。
无连接服务将所有的数据包被独立地注入到网络中,每个数据包携带完整的目的地址,在网络中被独立路由(被每一跳路由器根据本身的路由表确定下一步的转发线路)。数据包之间由于网络状态的变化(反映到某些路由器路由表的变化,从而导致从当前路由器以后路径的变化)可能经过不同的路径。所谓“独立”,指的是任意两个数据包的路径没有相关性。
面向连接的服务事先为一次传输确定一条路径(虚电路,虚的含义是使用一条线路的部分资源而非全部),本次传输中的所有数据包使用同样的路径递交。虚电路使用一个标识符标识本虚电路。虚电路标识符具有“局部(本地)”特征,即每台路由器可能选择不同的标识符。标识符在整条路径上不断变化,不影响数据转发。每个数据包携带一个虚电路标识符用于中间路由器的转发,每经过一个路由器,虚电路标识符的取值可能变化。
二者可以总结为如下表格:
| 问题 | 数据包网络 | 虚电路网络 |
|---|---|---|
| 电路建立 | 不需要 | 需要 |
| 寻址 | 每个包包含全部的源和目的地址。 | 每个包包含简短的VC号。 |
| 状态信息 | 路由器不保留连接状态。 | 针对每个连接,每条VC都需要路由器保留其状态。 |
| 路由方式 | 每个数据包被单独路由。 | 建立VC时选择路由,所有包都遵循该路由。 |
| 路由器失效的影响 | 没影响,除了那些路由器崩溃期间丢失的包。 | 穿过故障路由器的所有VC都将崩溃。 |
| 服务质量 | 困难 | 容易,如果在预先建立每条VC时有足够的资源可以分配。 |
| 拥塞控制 | 困难 | 同上 |
¶ 路由算法
路由算法和路由协议的最主要的目标是为数据传输寻找一条(或多条)从源节点到目的节点的路径。这条路径应该能够满足给定的优化目标要求,应该能够反应当前的网络状态(包括网络拓扑—网络的连接情况,和网络的流量负载状况等)。
路由算法和路由协议是路由器中的一个重要功能,目标是建立和维护存放在路由器中的路由表。路由器还有另外一个重要功能,即使用路由表对数据进行的转发功能(被路由功能,如IPv4)。
路由算法是一个优化问题的求解,更为精确的说,是一个受限的优化问题的求解,可以很复杂,有些情况下是NP-hard问题。常用的路由算法使用较为简单的启发式算法求解。
¶ 最优化算法
最优化原则:如果路由器J在从路由器I到路由器K的最优路径上,那么从J到K的的这一段子路径必定是从J到K的最优路径。
最优化原则可以避免环路,即遵循最优化原则计算的路径没有环路,但是当网络拓扑收集不准确时,可能造成环路。
路由算法就是计算寻找以所有路由器为目标节点的汇聚树。
汇聚树:从所有源节点到一个指定目标节点的最优路径的集合构成一棵以目标节点为根的树。汇聚树分布保存在路由节点中,每个路由节点只需保存一步路由(下一跳)。从每个路由器开始的每步综合起来,就是从本节点到指定目标节点的最优路径。
动态路由/自适应路由算法:每个路由器能够根据当前的网络状态(网络拓扑)计算从自己到所有其它路由器的最短路径,包含两个方面的内容:获得当前的网络状态,根据网络状态计算路由。
根据获得当前网络状态和计算最短路由的不同,常见的路由算法有:
- 距离矢量路由算法
- 链路状态路由算法
- 二者的混合
¶ 泛洪/扩散算法
泛洪路由的基本想法是源节点将消息以分组的形式发给其相邻的节点,相邻的节点再转发给它们的相邻节点,继续下去,直至分组到达网络中所有的节点。
泛洪算法不需要事先知道网络的拓扑结构图,所以适用于协议开始时传递拓扑信息。
¶ 距离矢量路由算法 DVR
距离矢量路由的原理是每个路由器维护一张表,表中列出了当前已知的到每个目标的最佳距离,以及所使用的链路,这些表通过邻居之间相互交换信息而不断被更新,最终每个路由器都了解到达每个目的地的最佳链路,其过程包括两个步骤:
- 每台机器周期性的将自己的距离矢量发送给自己的所有邻居。
- 每台机器根据邻居的距离矢量计算自己新的路由表。

但是距离矢量路由算法只是根据邻居的距离矢量计算自己的路由表,当计算一条路径时,无法判断邻居所说的最短路径是否通过自己(这是分布式算法本身固有的缺陷),所以可能带来环路问题。
环路的补救与避免:
- 定义最大值。在RIP (Routing Information Protocol)路由协议中,允许跳数最大值为16 ,这个方案只是补救措施,不能避免环路产生。
- 水平分割。水平分割的思想就是在路由信息传送过程中,不再把路由信息发送给接收此路由信息的接口上(原因:路由器将从某个邻居学到的路由信息又告诉了这个邻居)
环路带来的缺陷是数据在网络中无休止地循环(IP协议中规定了数据分组在网络中的最大存活时间,用以克服环路);以及算法收敛慢,尤其是线路出现问题时很难达到收敛。
导致无穷计算问题的一个重要原因是把从对方获知的,但在对方已不再有效的信息当成有效信息再传送给对方,使对方当成有效信息使用。因此只要不把从某邻居节点获得的路由信息再发送给该邻居节点,就能基本上避免无穷计算问题。
¶ 链路状态路由算法 LSP
链路状态路由算法中,一个结点检查所有直接相连的链路状态,并将所得的状态信息发送给网络上的其他所有结点,而不是仅仅发送给相邻的结点。包含如下过程:
- 发现邻居节点(HELLO)
- 测量线路开销或延迟(ECHO)
- 构造链路状态分组(发送标识,seq,age)
- 发布链路状态分组(泛洪算法)
- 计算新最短路由(Dijkstra算法)
链路状态路由算法在网络内的可靠性扩散过程:
-
每个分组都包含一个序列号。当一个新的链路状态分组进来的时候,路由器在已经看到的分组列表中检查这个新进来的分组:
-
如果他是新的,那么除了它到来的那条线路之外,在其他的线路上全部转发该分组。
-
如果他是一个重复分组,则将他丢弃。
-
如果一个分组的序列号小于当前所看到过的来自该源路由器的最大序列号,则作为过时分组而拒绝。
-
-
每个分组的序列号之后包含年龄信息,每秒钟将年龄减一,当年龄=0时,来自该路由器的信息被丢弃。
-
当一个链路状态分组被扩散到一个路由器中时,他并没有立即加入到队列中等待传输,而是放到一个保留区中等待一段时间。如果在这个分组被发送出去之间,另一个来自同一个源路由器的链路状态分组到来,那么比较他们的序列号,如果相等则丢弃,不相等则把老的丢弃。
-
所有的链路状态分组都要被确认。
与距离矢量路由算法相比:
- 链路状态路由算法需要更多的内存和计算。
- 不存在慢收敛的问题。
- 链路状态路由某个路由将自己的路由状态告诉全部路由器,而距离矢量只是将路由状态告诉给邻居路由器即可。
- 链路状态路由算法向本自治系统中的所有路由器发送消息,这里使用的是泛洪法(路由器通过所有端口向相邻路由器发送信息,而每一个相邻路由器又发给所有相邻路由器,但不再发给刚才发来信息的路由器)。而距离矢量路由算法是仅仅向自己相邻的几个路由器发送信息。
- 链路状态路由算法发送的信息就是与本路由器相邻的所有路由器的链路状态,但这只是路由器所知道的部分信息。“链路状态”就是说明本路由器都和哪些路由器相邻,以及该链路的“度量”。而在距离矢量路由算法中,发送的信息是本路由器所知道的全部信息,即整个路由表。
- 只有当链路状态发生状态时,链路状态路由算法路由器才用泛洪法向所有路由器发送此信息,并且更新过程收敛得快,不会出现距离矢量路由算法“坏消息传得慢”的问题。而在距离矢量路由算法中,不管网络拓扑是否发生变化,路由器之间都会定期更换路由表的信息。
¶ 层次路由
随着网络规模的增长,路由器的路由表也成比例增长,结果是路由器效率下降,成为网络服务的瓶颈。解决之道是将网络分层,采用分层路由之后,路由器被划分成区域,每个路由器知道如何将数据包路由到自己所在区域内的目标地址,但是对于其他区域的内部结构毫不知情。
¶ 广播路由
广播路由算法的目的是将一个分组从源节点传送到网络中的所有节点。广播路由算法的一个重要应用是路由器的路由表的建立。
几种算法:
- 算法1:分别发送分组到每个目的端
- 算法2:扩散法(Flooding)
- 算法3:多目的地路由选择
- 算法4:利用发起广播的路由器的汇集树或利用生成树
- 算法5:逆向路径转发
¶ 多播路由
实现方法:
- 良好的小组管理机制
- 创建和取消小组
- 允许进程进入、离开小组
- 发送时,第一个路由器检查生成树,修剪小组成员不能到达的线路
¶ 移动主机路由
术语:
- 静态用户:从不移动的用户
- 移动用户:非静态用户(迁移用户、漫游用户)
- 外地代理:管理所有来当地的动态用户
- 本地代理:管理本属本区域,但当时正在外地的用户
典型的登录过程:
- 外地代理定期广播分组,宣布自己的存在及地址;同时,移动主机可以广播,问“这里有没有外地代理?”
- 移动主机登录到外地代理
- 外地代理与移动主机的本地代理联系
- 本地代理检查安全性信息
- 外地代理得到本地代理的确认后,建立一个表项,并通知移动主机已经登录了
¶ 拥塞控制
拥塞:网络中存在太多数据包导致数据包被延迟和丢失,从而降低了传输性能。当拥塞出现后,有可能遭遇拥塞崩溃。
完整的流量控制应该是网络层(RED协议)和传输层(TCP慢启动)共同配合的任务。
拥塞产生的原因:
- 传输层注入太多的、超过网络处理能力(网络容量)的数据。
- 网络层路由协议不能充分使用网络资源、不能适应流量的分布变化。
- 网络资源不足以支持流量。
虚电路子网中的拥塞控制主要有两个方式:
- 准入控制
- 资源预留
数据报子网中有三种方式:
- 警告位
- 抑制分组
- 逐条抑制分组
¶ RED协议
随机早期检测(RED,Random Early Detection):为了确定何时开始丢弃数据包,路由器需要维护一个运行队列长度的平均值。当某条链路上的平均队列长度超过某个阈值时,该链路就被认为即将拥塞,因此路由器随机丢弃一小部分数据包受到影响的发送方会发现丢包,然后传输协议将放慢速度)。
采用随机丢包而不用抑制包的原因:当拥塞时,若路由器向发送方发抑制包,那么大量的抑制包反而会加重拥塞。所以网络层解决拥塞的思路就是防患于未然,在局面变得毫无希望前让路由器舍弃负担。
¶ 服务质量
网络层的服务质量包括如下几个方面:
- 可靠性:网络信息系统能够在规定条件下和规定的时间内完成规定的功能的特性。
- 延迟(delay):数据(一个报文或分组)从网络(或链路)的一端传送到另一端所需要的总的时间。
- 抖动(jitter):延迟的变化(即标准方差)或者数据包到达时间的变化。
- 带宽
资源预留主要包括三个部分:
- 带宽
- 缓冲区:又包括客户端缓冲数据包和服务端流量整形。
- CPU周期
¶ 流量整形
流量整形(Traffic Shaping):调节进入网络的数据流的平均速率和突发性所采用的技术。漏桶算法和令牌桶是两个主要的流量整形技术。
漏桶算法:在每个主机连接到网络的接口都包含一个漏桶,即一个有限长度的内部队列。如果当队列满的时候,又有一个分组到来,则该分组被丢弃。每过一个常数时间才允许把一个分组放到网路上,这种机制可以将主机内用户进程发送出来的一个不均匀分组流变成了网络上一个均匀分组流,把突发分组流变得很平静,从而极大降低了拥塞的几率,而且无论负载突发性如何,漏桶算法都强迫输出按平均速率进行。
令牌桶算法:漏桶中保存的是令牌,这些令牌由时钟产生,每隔T产生一个。要使一个分组被传送出去,它必须抓住并销毁一个令牌,令牌桶允许将令牌即许可权保存起来,直至到达桶的最大尺寸n,当令牌桶满后,令牌桶丢弃令牌,不丢弃分组。从本质上讲,令牌桶所做的事情是:允许突发流量,但是不得超过一个预定的最大长度
令牌桶最大速率传输时间的计算:Ms=B+Rs(s最大速率传输时间,M最大传输速率,B桶的容量,R令牌的产生速率)
二者的比较:
- 流量整形策略不同:漏桶算法能够强行限制数据的传输速率,令牌桶算法能够在限制数据的平均传输速率的同时还允许某种程度的突发传输。因此,漏桶算法对于存在突发特性的流量来说缺乏效率。
- 丢弃对象不同:当令牌桶满了之后,令牌桶丢弃令牌,但是不丢弃分组,相反的,在漏桶算法中丢弃分组。
¶ 网络互联
当两端网络使用相同的网络,中间网络使用的一种封装技术。在中间传输时使用新的协议头驱动,在两端网络传输时使用原有的协议头驱动。隧道技术是解决不同种类网络互联一个特例的方法,用于解决发送和接收网络属于同一类型网络,但是中间经过不同类型网络的情况。
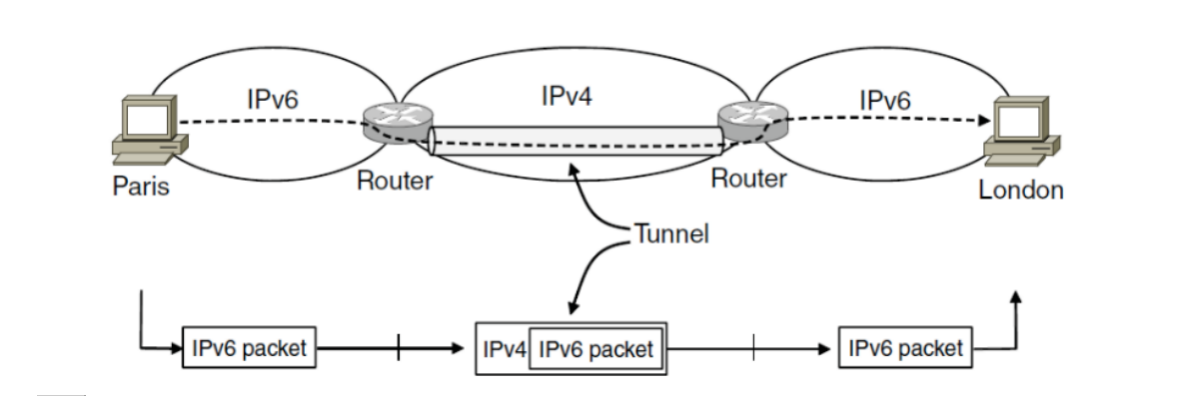
隧道技术(Tunneling):是一种通过使用互联网络的基础设施在不同网络之间传递数据的方式。使用隧道传递的数据(或负载)可以是不同协议的数据帧或包。隧道协议将其它协议的数据帧或包重新封装然后通过隧道发送。新的帧头提供路由信息,以便通过互联网传递被封装的负载数据。
¶ Internet 网络层
¶ IPv4协议
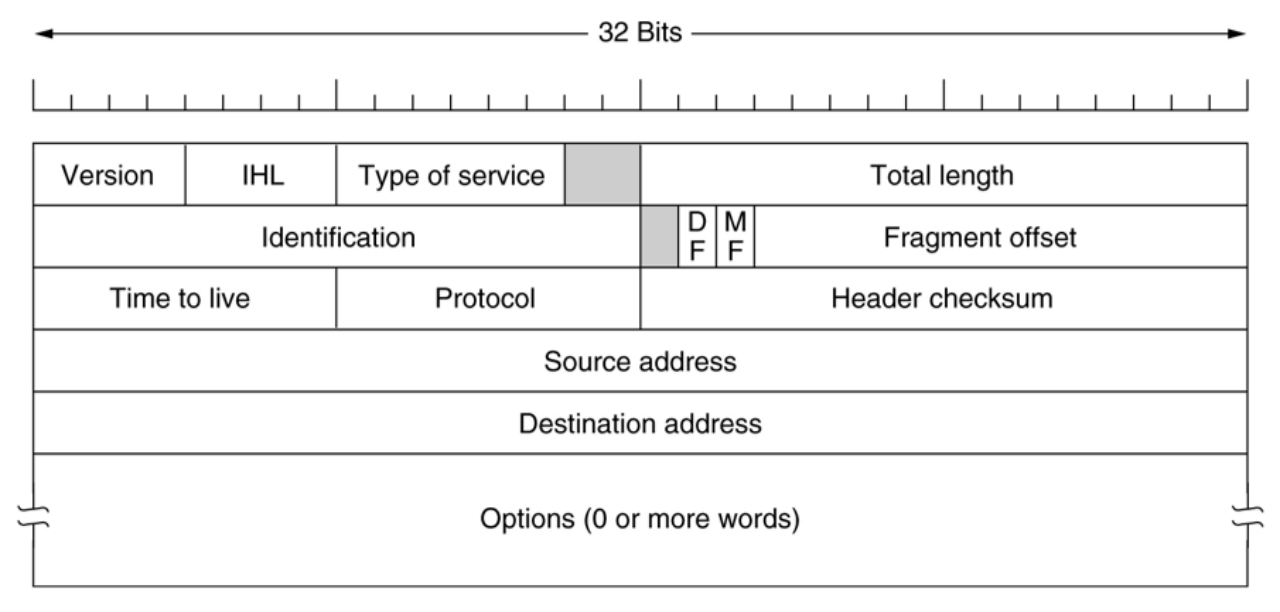
IPv4 协议的帧结构不需要记住长度,知道有哪些部分就好,综合题中会给出相应的信息作为参考。
IPv4 帧分为头部和净荷载,头部占 20 - 60 字节,包含如下部分:
-
Version:版本号。
-
IHL:协议头部长度。
-
Type Of Service:服务的类型,后两位携带显式拥塞通知。
-
Total Length:总长度(最长65535字节)。
以太网的最大传送单元MTU为1500字节,因此当一个IP数据报封装成帧时,数据报的总长度不能超过下面数据链路层的MTU值。
-
Identification:标识分段是否属于同一个数据包。
-
DF, Don't Fragment:不分段标识位,取0时允许分片。
-
MF, More Fragment:更多的段,除数据包中最后一个段外,其余皆为1,表示后面还有分片。
-
Fragment Offset:段偏移(最多8192个段),占13位。以8个字节为偏移单位,因此每个分片的长度一定是8字节(64位)的整数倍。
-
Time to Live:生命周期(255秒),即数据报在网络中可通过的路由器数的最大值。路由器在转发分组之前,先把TTL减1,若TTL被减为0,则该分组必须丢弃。
-
Protocol:传输层使用的协议,即分组的数据部分应该交给哪个传输层协议,TCP为6,UDP为17。
-
Header Checksum:头部校验和。
-
Source Address、Destination Address。
-
Options。
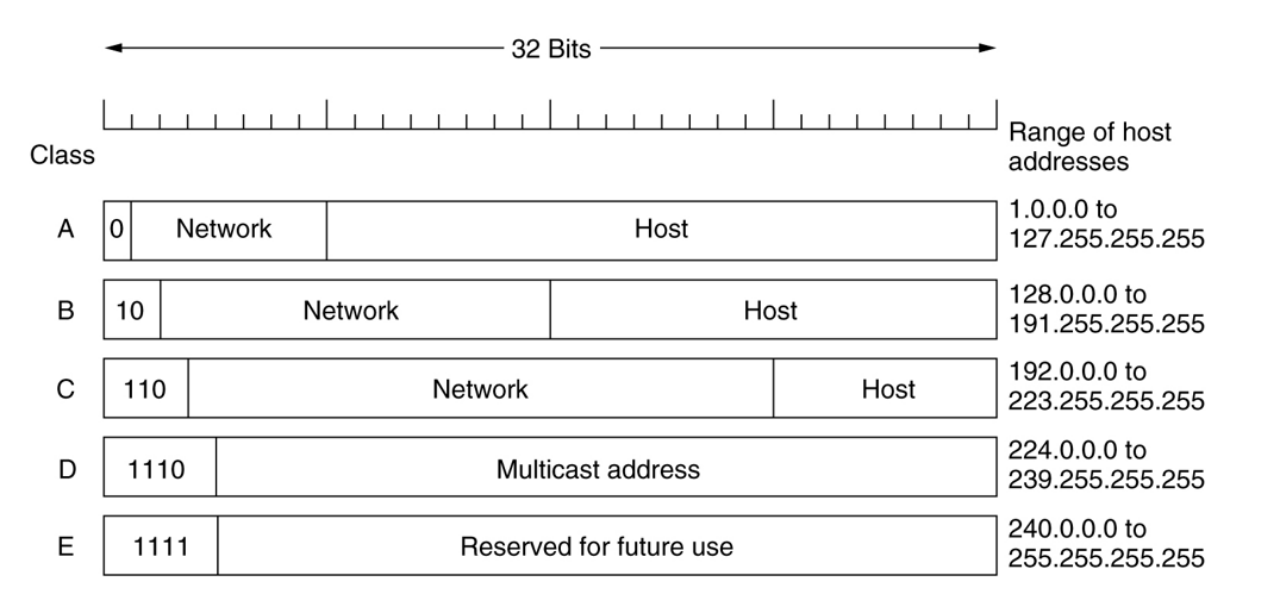
IP地址由网络号和主机号构成,共32位,一般使用十进制表示法。
网络号对应网络中一块连续的IP地址空间。路由器仅仅根据地址的网络部分即可转发数据包,只要每个网络都有唯一的地址块,对路由器来说网络地址的主机部分并不重要,因为同一网络的所有主机都在同一个方向,只有当数据包到达他们的目的地网络后才被转发到正确的主机。
按照网络号的前八位进行划分,总共有5类网络:
-
A类:0~127:保留给政府机构。
10.X.X.X 是私有地址,范围 10.0.0.0 - 10.255.255.255。
-
B类:128~191:分配给中等规模的公司。
私有地址范围是 172.16.0.0—172.31.255.255
-
C类:192~223:分配给任何需要的人。
范围 192.168.0.0—192.168.255.255。
-
D类:224~239,组播地址。
-
E类:240~254,保留为研究测试使用。
一些特殊的IP地址:
- 0.0.0.0 表示本网络上的本主机。
- 255.255.255.255 限制广播地址,这个地址不能被路由器转发。
- 127.0.0.0 保留作为环路自检地址,此地址表示任意主机本身,目的地址为环回地址的IP数据报永远不会出现在任何网络上。
- 主机号全为0表示网络本身。比如在192.168.0.0/24的子网中,192.168.0.0表示这个子网本身。
- 主机号全为1表示本网络的广播地址。比如,在 192.168.0.0/24 的子网中,192.168.0.255 表示这个子网的广播地址。
子网掩码是一种用来指明一个IP地址的哪些位标识的是主机所在的网络地址以及哪些位标识的是主机地址的位掩码。
¶ 无类域间路由(CIDR)
无类域间路由(CIDR)是在变长子网掩码的基础上提出的一种消除 A,B,C 类网络划分,并且可以在软件的支持下实现构造超网的一种IP地址的划分方法。
说白了,以前使用五类网络的划分太浪费,CIDR这种技术配合子网掩码可以实现更灵活的网络划分。
其原理包含两部分:
- 聚合:将子网网络号最大公共部分聚合为新的网络号。
- 转发:将目的地址分别于路由表中的每一项网络号的子网掩码进行比对,选择最长匹配的网络表项进行转发。
通过使用子网掩码可以对 IP 网络进行划分,也就是考试中会出现的划分子网 IPv4 地址的问题。在进行子网划分前,需要知道原本的A、B、C等网络分类在申请流程、使用成本、IP地址利用率等问题上都存在问题,因此,一个想法(也就是CIDR)便是将原本的主机号取出一部分,用来作为对原本网络号的进一步分类,也就是所谓的子网号,这样便在一个网络下面通过主机号的某些位区分出了新的子网。
例如,原本
192.168.0.0是一个B类网络,我们可以定义192.168.1.0为他的一个子网,只能容纳254(除去网络地址和广播地址)台主机。
但是,随之而来的一个问题就是如何让计算机和其他网络设备知道那里是网络/子网号、哪里是主机号,这就需要同时使用子网掩码进行表示。其实,子网掩码的与操作就是计算出对应的网络号,并将主机号全部抹0,如下图所示:
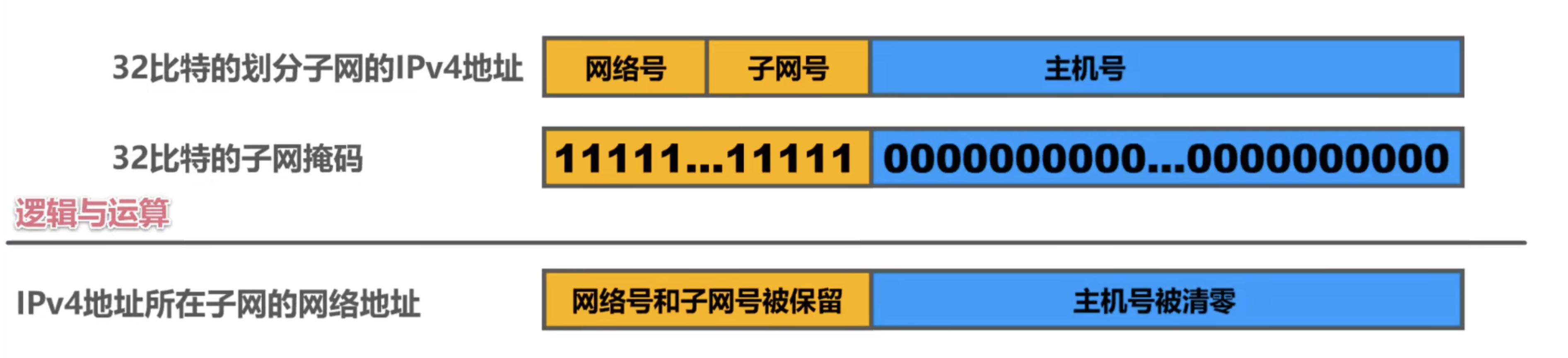
对于划分过程,建议直接观看子网划分视频学习。
路由聚合(Route Aggregation)指把多个小前缀的地址块合并成一个大前缀的地址块的过程。
最长前缀匹配(最佳匹配)是指使用CIDR时,路由表中的每个项目由“网络前缀”和“下一跳”组成。在查找路由表时可能会得到不止一个匹配结果,应当从匹配结果中选择具有最长网络前缀的路由,因为网络前缀越长,其地址块就越小,因为路由就越具体。
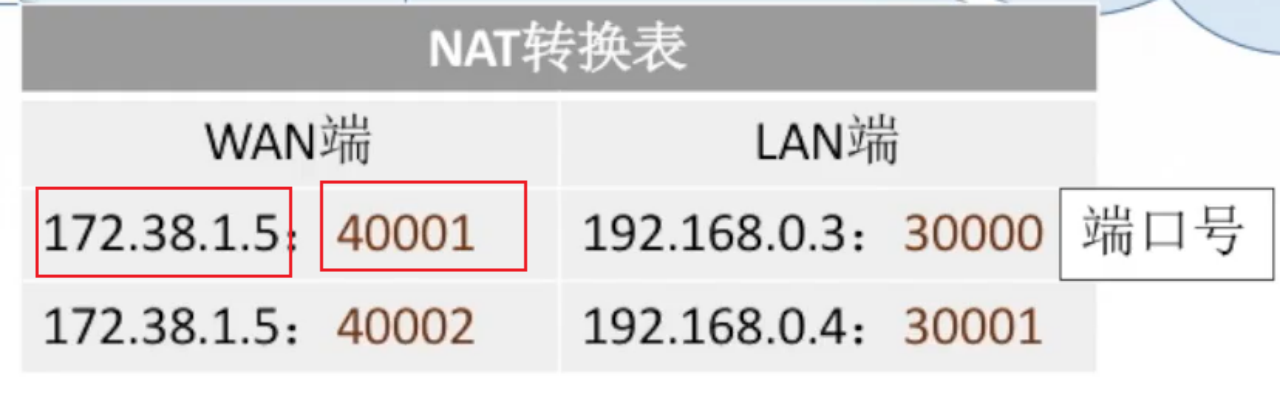
¶ 网络地址转换(NAT)
NAT技术通过将专用网络地址转换为公用地址,从而对外隐藏了内部管理的IP地址。
NAT有这些特点:
- 解决了IP地址短缺问题。解决策略:
- 动态分配IP
- 迁移到IPv6
- 多台主机共用一个 IP。
- NAT的思想是设定两套IP地址,内网相对于外网来说共用一个public地址;而在内网中,每台机器对应一个private 地址。
- 内网之间的通信使用 private 地址,当想要向外网发送消息时,只需将源地址替换为内网共用的 public 地址。
- 当外网向内网发送消息时,因无法区分内网的主机,所以引入了 port。将私有IP与端口号影射成新的port,当与这个端口号交互时,根据影射算法可以知道私有IP。
NAT存在的问题:
-
NAT违反了IP的结构模型,多个主机可以使用一个IP地址。
-
NAT将Internet从一个无连接网络变成一个面向连接网络特有的形式。
-
违反了最基本的协议分层原则,传输层的数据不再对网络层透明。
NAT技术在转换过程中会修改数据包的源IP地址、目的IP地址、源端口号和目的端口号等信息。这种修改操作会影响到传输层对网络层数据的处理,使得传输层对网络层的数据不再透明。
-
一旦进程不适用TCP或UDP协议,NAT将无法准确定位。
-
端口号是16位的,所以最多可以将 65,536 台机器映射到一个IP地址上。
NAT 工作时,出境数据包进入NAT盒子后,其源地址被客户的真实IP地址取代,而且TCP的源端口号字段被一个索引值取代,该索引是NAT盒子的地址转换表中 65536 个表项中的一个,该表项包含了原来的IP地址和原来的端口号,重新计算IP头和TCP头的校检和,并将校检和插入数据包中;入境的一个数据包到达NAT盒子时,源端口取出作为索引值找到内部的IP地址和原来的端口号,插入数据包,重新计算IP头和TCP头的校检和,插入到数据包。
¶ 因特网控制协议
主要的因特网控制协议有ICMP、ARP、DHCP、RIP、OSPF和BGP协议。
Internet控制消息协议(ICMP):向数据包源端报告有关事件。每一种ICMP消息类型都被封装在一个IP分组中,允许主机或者路由器来报告差错和异常情况 :
- 目的地不可达(DF,“小数据包网络”)。
- 超时(TTL为零)。
- 参数问题,无效的头域。
- 源端抑制:抑制分组。
- 重定向:告诉路由器有关地理信息。
ARP,Address Resolution Protocol(广播协议):地址解析协议。用于完成IP地址到MAC地址的映射。请求和应答:使用地址解析协议(IP->MAC地址的映射)。
工作的过程:
- IP层协议通过目标机器的IP地址和自己的子网掩码,检查它跟自己是否属同一网络。
- 如果属于同一网络,就直接在本网络内查找这台机器的MAC。检查ARP高速缓存,如果以前两机有过通信,在A机的ARP缓存表应该有B机IP与其MAC的映射关系,有对应表项则写入MAC帧,没有则用目的MAC地址为FF-FF-FF-FF-FF-FF的帧封装并广播ARP请求分组,则同一局域网所有主机都能收到该请求。目的主机收到请求后就会向源主机单播一个ARP响应分组,源主机收到后将此映射写入ARP缓存。
- 如果IP协议通过计算发现目标地址与自己不在同一网段内,就直接将交由路由处理,也就是将路由的MAC取过来,至于怎样得到路由的MAC:先在ARP缓存表找,找不到可以利用广播。路由得到这个数据帧后,再跟目标主机进行联系,如果找不到,就向主机A返回一个超时的信息。
- 如果发送的IP地址不在本局域网上则发送给默认网关(默认网关:默认网关具有网络上的最低地址(是路由器的IP地址))。
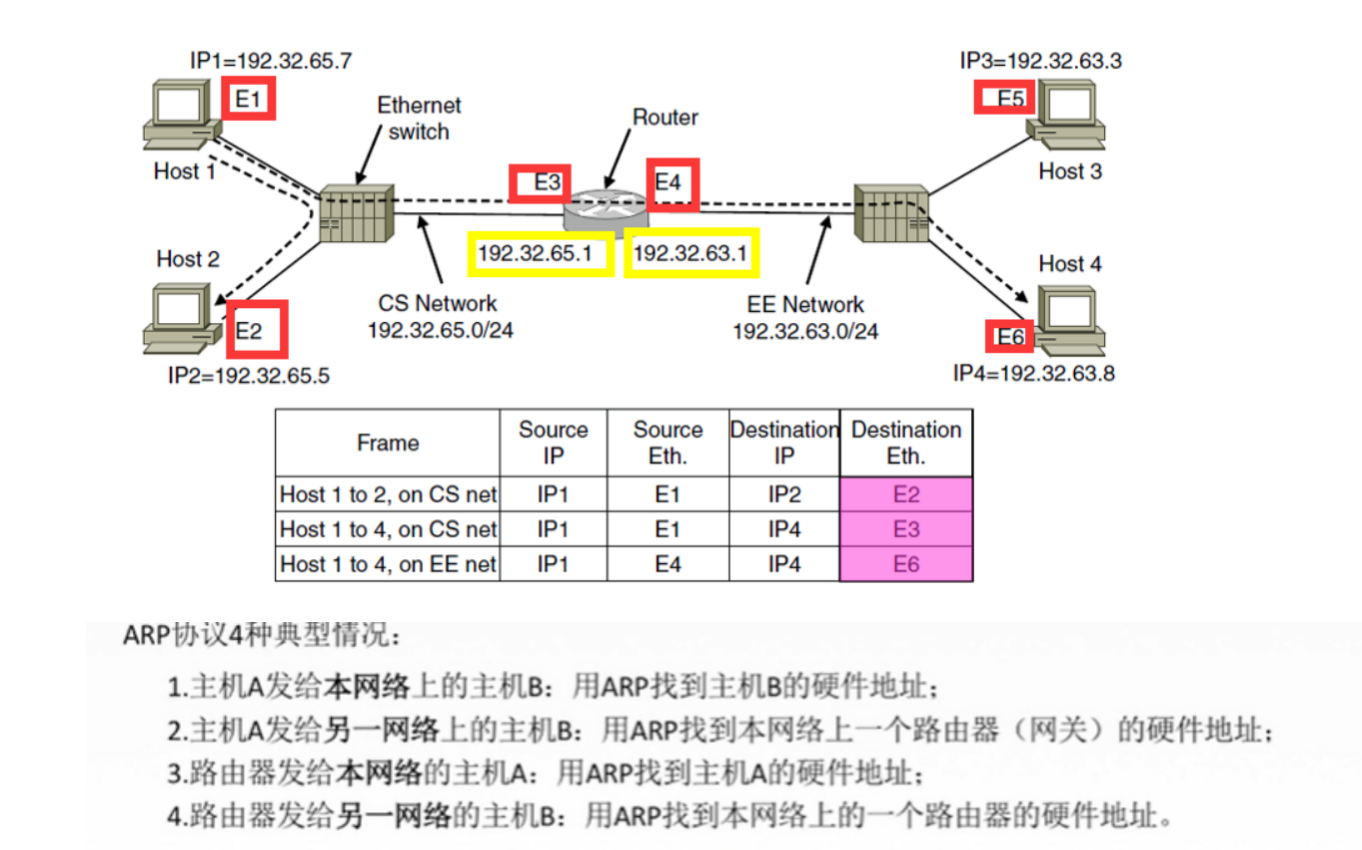
ARP 是解决同一个局域网上的主机或路由器的IP地址和硬件地址的映射问题。如果要找的这个主机和源主机不在同一个局域网上,那么就要通过ARP协议找到一个位于本局域网上的某个路由器的硬件地址,然后把分组发送给这个路由器,让这个路由器把分组转发给下一个网络,剩下的工作就由下一个网络来做。
ARP的两个优化:
- 缓存。
- 每个新主机开机时广播。
代理ARP:
- 路由器不转发以太网级别的广播信息
- 主机将发往其他网络的广播信息发送给本地代理
反向地址解析协议(RARP):将MAC映射到IP地址,只是ARP反过来罢了。缺点:目标地址全1,路由器不转发
ARP、RARP都是广播协议——网络上的每一台机器都能收到请求。
BOOTP(bootstrap):使用UDP数据报,路由器转发。缺点:新机器加入,需要手动配置(MAC,IP)
DHCP,Dynamic Host Configuration Protocol(动态主机配置)协议:计算机启动时向 DHCP服务器请求 IP 地址,DHCP 服务器给主机分配一个空闲的 IP 地址。服务器用MAC地址标识该主机。
租赁技术:为每个分配的IP 地址制定一个固定的时间,租赁期满前,主机必须重新请求续订。
¶ 路由选择协议
接下来介绍路由选择协议。首先要明确的是,路由协议与路由选择算法有着十分紧密的关系,RIP、OSPF协议分别是用了距离矢量和链路状态算法,但协议内除了规定算法的使用方式以外,还有一些附加的规定以充分优化路由选择过程。路由器工作在参考模型的网络层,他所做的工作其实是将数据包在一个网络(局域网)和另一个网络之间传递,我们提出一个新的概念自治系统用于描述这里的小网络。
自治系统(AS,Autonomous System):有权自主地决定在本系统中应采用何种路由协议的小型单位。
在自治系统内部使用的路由选择协议有很高的自由度,对于两个自治系统而言,双方用什么路由协议都无所谓,因为自治系统内部的路由选择过程协议仍是统一的;而自治系统之间的通信,则有网关(出入口路由)通过统一的路由选择协议进行控制。
根据路由选择/网关协议的工作环境,可以分为两种协议:
-
内部网关协议(Interior Gateway Protocol,IGP):在一个自治系统内部使用的路由选择协议,它与互联网中其他自治系统选择什么路由选择协议无关。
-
外部网关协议(Border Gateway Protocol,BGP):用于连接自治域。是一种外部网关路由协议。是一种改进了的距离矢量路由协议,保存完整的路由信息。
BGP 的关键作用是尊重网络的政策约束(考虑政治约束)。
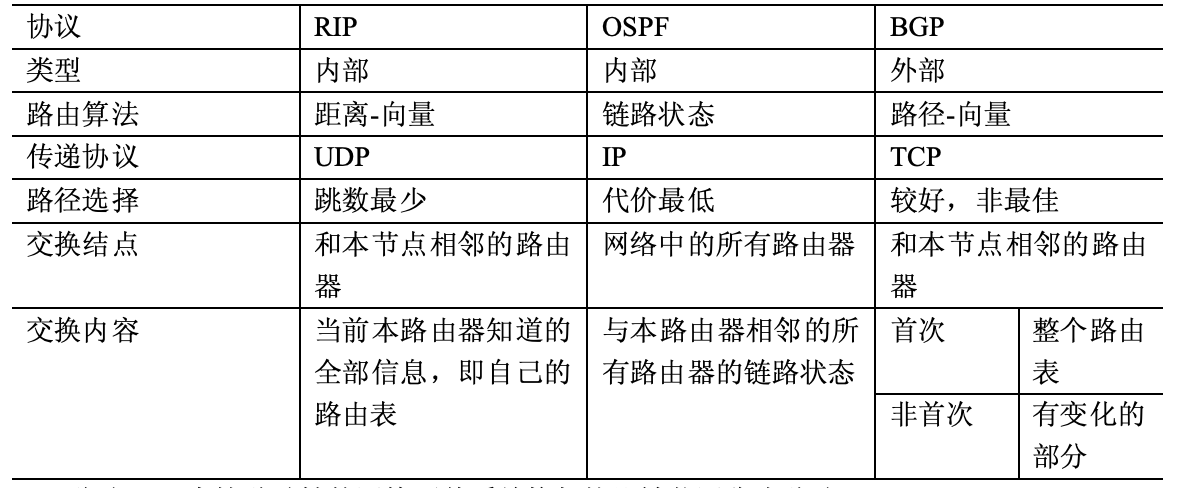
二者只是一种比较高层次的、抽象的分类,对于BGP来讲通常只有一种常用的路径矢量算法;IGP协议则更多一些,包括各种私有协议以及常见的RIP协议和OSPF协议:
- 路由信息协议(RIP,Routing Information Protocol):使用距离矢量算法的协议。
- OSPF协议:开放的最短路径优先协议,是一种常用的内部网关协议,属于链路状态路由协议的一种。
只有链路状态变化时,路由器才向所有路由器发送。
¶ 传输层
传输层提供应用进程之间的逻辑通信(即端到端的通信)。与网络层的区别是,网络层提供的是主机之间的逻辑通信。
复用和分用:复用是指发送方不同的应用进程都可以使用同一个传输层协议传送数据;分用是指接收方的传输层在剥去报文的首部后能够把这些数据正确交付到目的应用进程。
传输层的复用分用功能与网络层的不同,网络层的复用是指发送方不同的协议的数据都可以封装成IP数据报发送出去,分用是指接收方的网络层在剥去首部后把数据交付给相应的协议。
传输层要对收到的报文进行差错检测(首部和数据部分),而网络层只检查 IP 数据报的首部,不检验数据部分是否出错。
传输层提供两种不同的传输协议:面向连接的TCP和无连接的UDP。而网络层无法同时实现两种协议(即网络层要么只提供面向连接的服务,如虚电路;要么只提供无连接服务,如数据报,而不可能在网络层同时存在这两种方式)。
端口(Port):应用层的各种协议进程与传输实体进行层间交互的一种地址,应用进程通过端口号进行标识,长度为16bit。端口能够让应用层的各种应用进程将其数据通过其端口向下交付给传输层,以及让传输层指导应当将其报文段中的数据向上通过端口交付给应用层相应的进程。
¶ 传输协议的要素
传输协议的要素包括寻址、建立连接三次握手、释放连接四次挥手、流控制和缓冲。
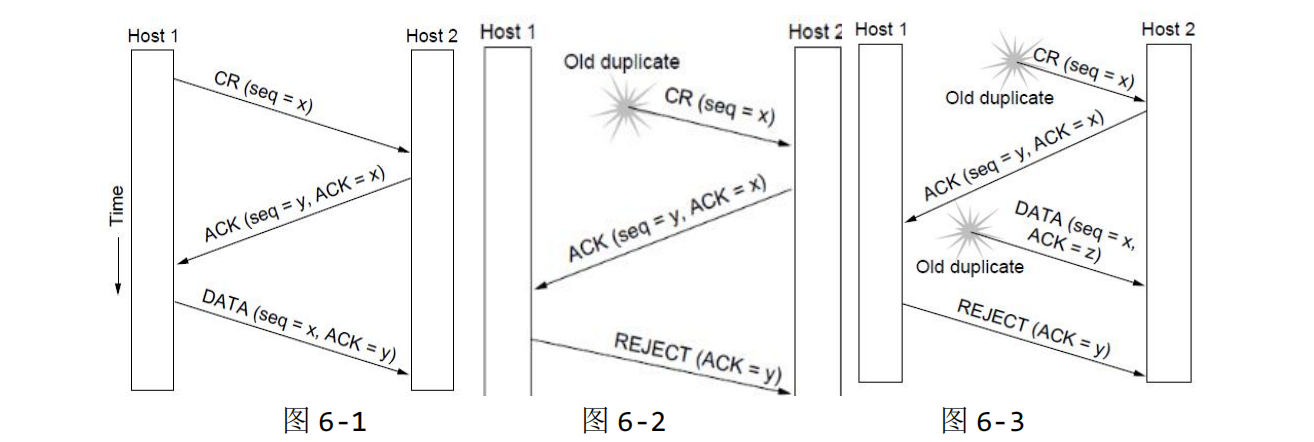
如上图所示,这是建立连接的三种情况:
- 图6-1是正常的三次握手建立连接的过程。(此图中的ack 值为下一次想要接收的第一个字节编号减一所得,下图亦然)。
- 图6-2这种情况是老的CR (Connection Request)重复分组出现了,它虽然引起了主机2发送相应的分组,但是主机 1根据主机 2发送分组的 ack 值可以发现这是异常情况, 所以拒绝(REJECT)。
- 图6-3这种情况是老的CR (Connection Request)重复分组和和老的数据重复分组出现的情况。虽然老的CR重复分组引起了主机2发送相应的分组,但是主机1根据主机2 发送分组的 ack 值可以发现这是异常情况,产生拒绝(REJECT);对于数据重复分组。主机 2根据分组的 ack 值可以发现这是异常情况。
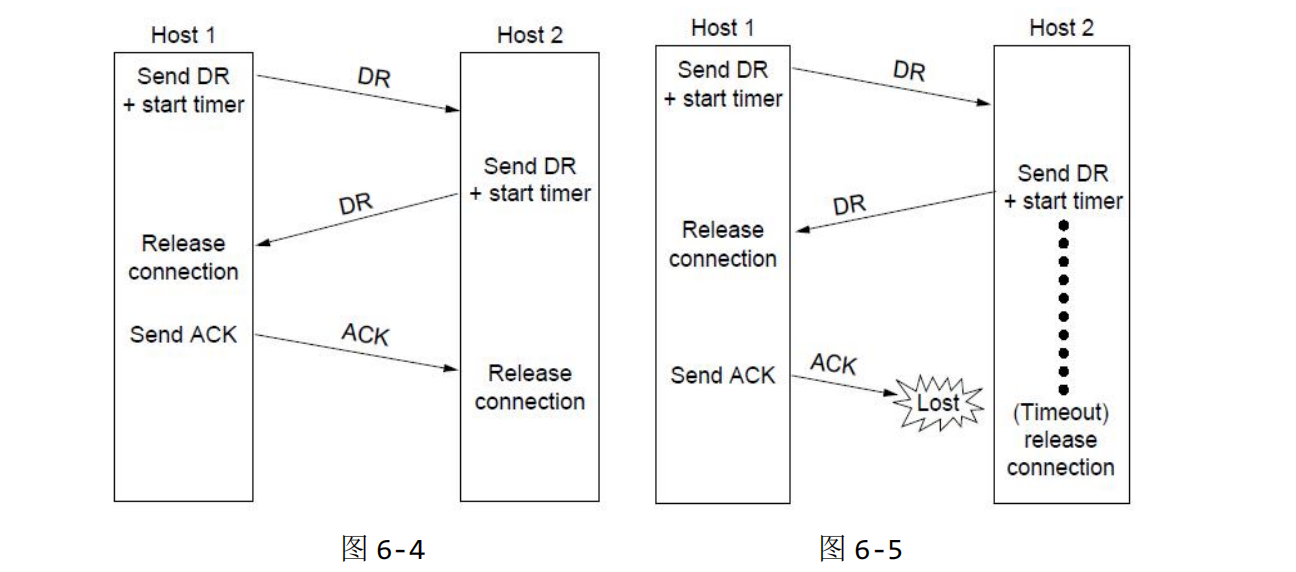
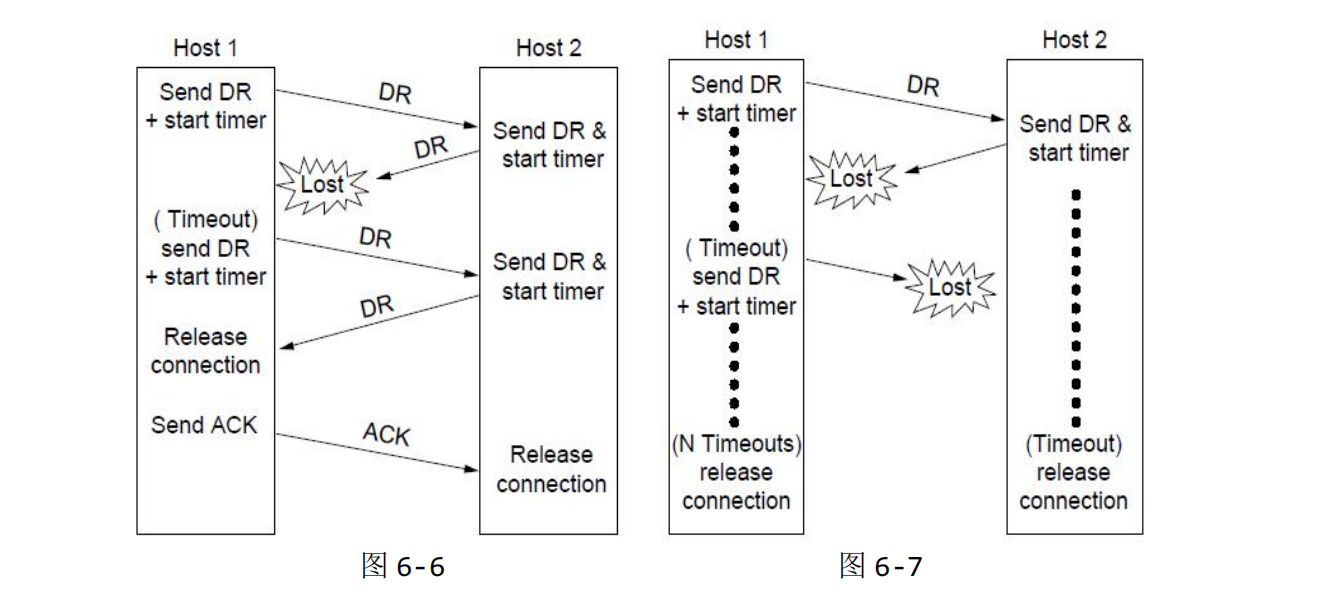
如上图所示,断开连接的四种情况:
- 图 6-4 是正常的三次握手断开连接的过程。
- 图 6-5 这种情况是最后主机 1 发出的 ack 丢失的情况,这时候,当主机 2 的计时器超时后,主机 2 就会释放连接。
- 图 6-6 这种情况是主机 2 给主机 1 的 DR(Disconnection Request)的应答丢失了,这种情况下,当主机 1 的计时器超时后,主机 1 会重新发送 DR。
- 图 6-7 这种情况是主机 2 给主机 1 的 DR(Disconnection Request)的应答和主机 1 后续的 DR 都丢失了,这种情况下,主机 1 经过 N 次重传之后,就会放弃,并且释放连接;而主机 2 在计时器超时之后也会释放连接。
¶ UDP与TCP的比较
在详细讨论 UDP 和 TCP 时,二者常被提及的一个特点就是 UDP 面向报文、TCP面向字节流,如下图所示。
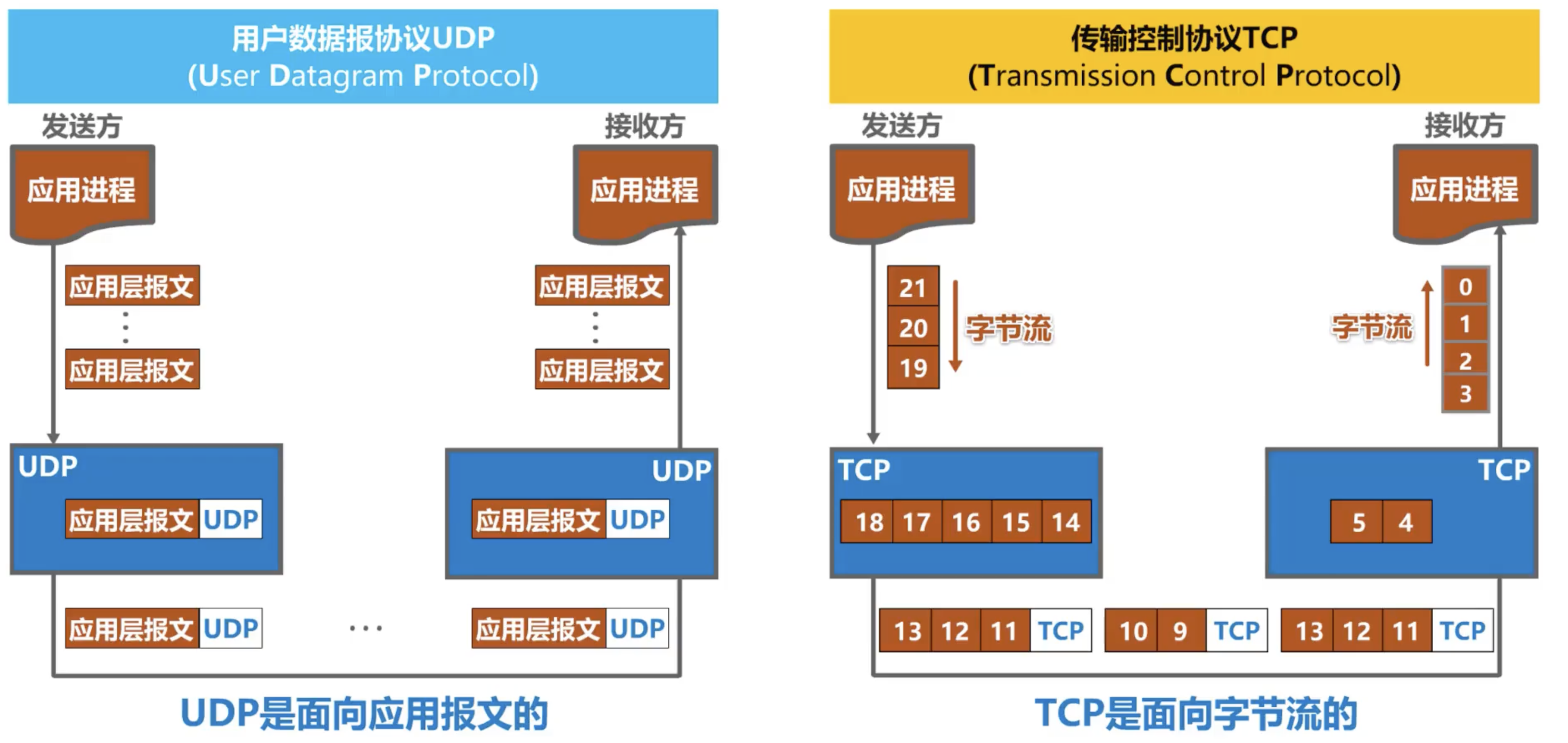
可以看到:
- UDP 只是对上层报文添加了 Header,所以是面向应用报文的传输。
- TCP 会将上层数据以字节为单位保存在缓冲区中,并按照一定规则选择其中的数据进行发送,因此 TCP 的操作都是以字节流为基础,这也是 TCP 能够实现拥塞控制、可靠传输等特性的原因。
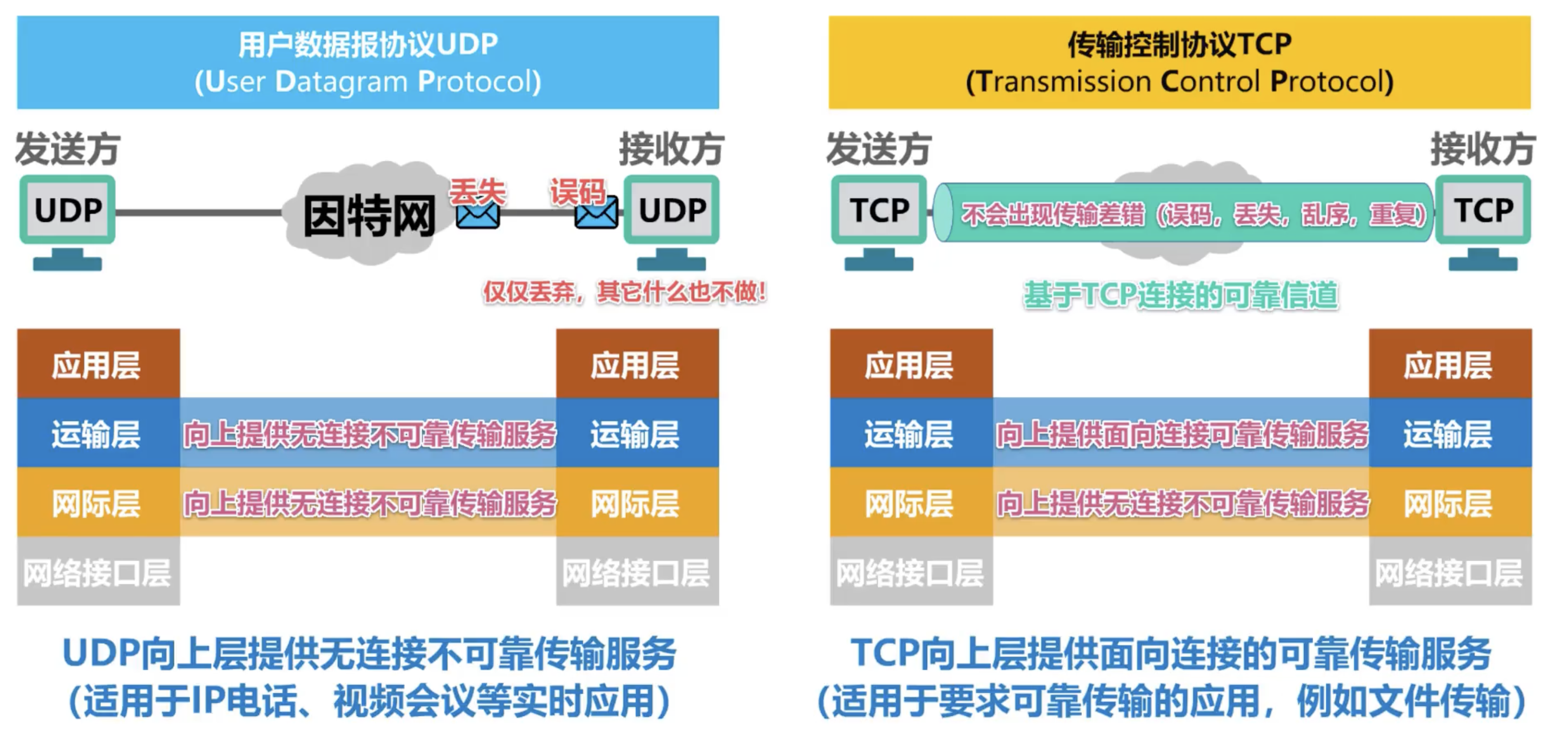
在提供的服务上,UDP 提供了无连接不可靠的传输服务,TCP则是面向连接的可靠传输服务:
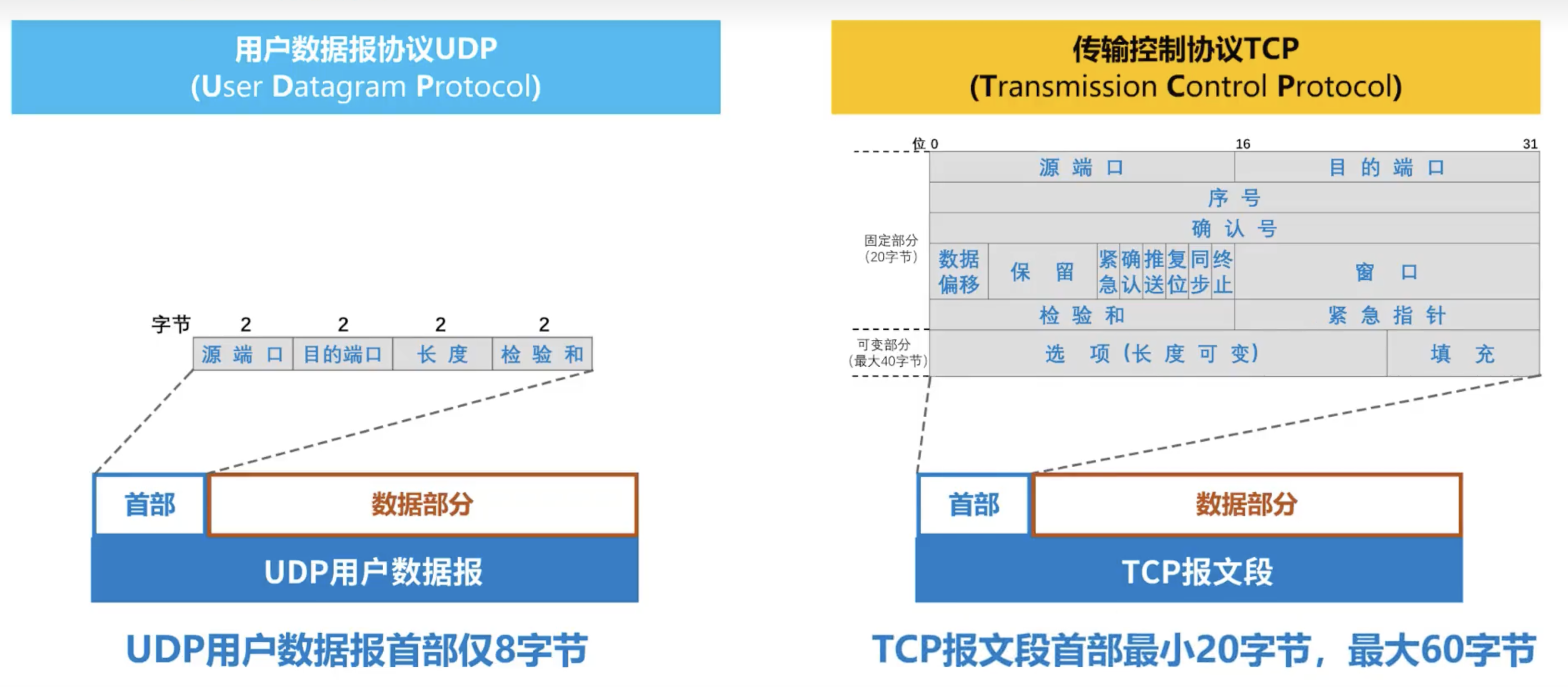
在头部结构上二者具有显著的区别:
常见的工作在 UDP 和 TCP 协议上的应用层协议如下图所示:
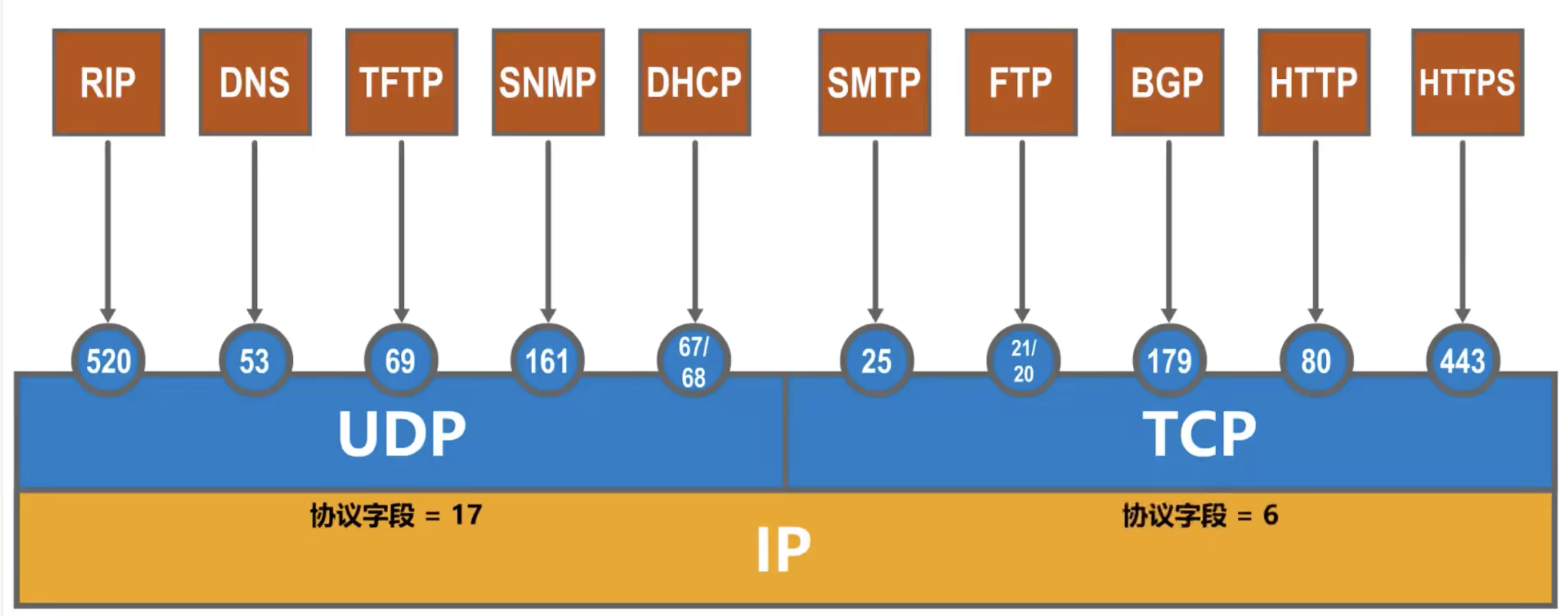
¶ UDP
UDP(User Datagram Protocol),用户数据报协议。
UDP的优点:
- UDP无需建立连接。因此UDP不会引入建立连接的时延。
- 无连接状态。不需要维护连接状态。
- 分组首部开销小。TCP有20字节的首部开销,UDP只有8字节。
- 应用层能更好地控制要发送的数据和时间。UDP没有拥塞控制,因此网络中的拥塞不会影响主机的发送效率。
UDP常用于一次性传输比较少量的网络应用,如DNS。UDP也常用于多媒体应用,如IP电话,实时视频会议等。可靠数据传输对于这些应用来说并不是最重要的,但是TCP的拥塞控制会导致数据出现大的延迟,这是不可容忍的。
UDP提供尽最大努力的交付,但并不意味应用对数据的要求不可靠,因此所有的维护传输可靠性的工作需要用户在应用层完成。
UDP是面向报文的。UDP对应用层交下来的报文,在添加首部后就向下交付给IP层,既不合并,也不拆分,而是保留这些报文的边界;接收方UDP对IP层交上来的UDP数据报,在去除首部后就原封不动地交给上层应用进程,和一次交付一个完整的报文。
UDP检验:二进制反码求和再取反。
IP数据报只检验IP数据报的首部,UDP检验是把首部和数据一起检验。
¶ TCP
¶ 模型和协议介绍
TCP(Transmission Control Protocol):传输控制协议,在不可靠的IP层之上实现的可靠的数据传输协议。
TCP的特点:
- TCP是面向连接的传输层协议。
- 每一条TCP连接只能有两个端点,每一条TCP连接只能是点对点的(一对一的)。
- TCP提供可靠的交付服务,保证传送的数据无差错、不丢失、不重复且有序。
- TCP提供全双工通信,允许通信双方的应用进程在任何时候都发送数据,为此TCP连接的两端都设有发送和接受缓存,用来临时存放双方通信的数据。
- 发送缓存:发送应用程序传给发送方TCP准备发送的数据;TCP已经发送但是没有接收到确认的数据。
- 接收缓存:按序到达但尚未被接收应用程序读取的数据;不按序到达的数据。
- TCP是面向字节流的。
TCP 帧结构如下图所示:
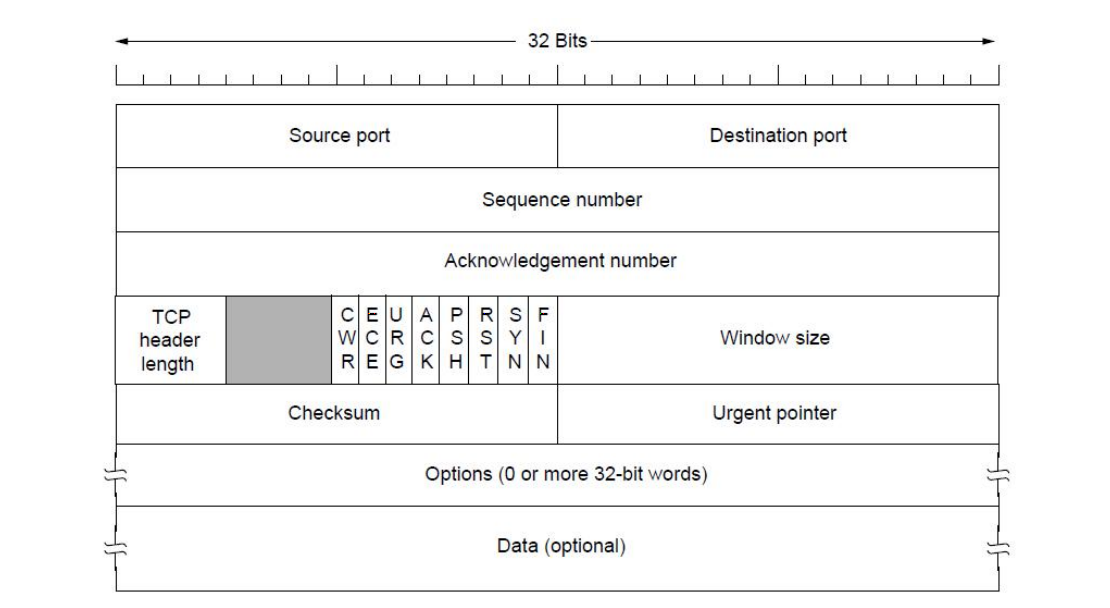
- 第一行是源端口(Source port)和目标端口(Destination port)信息。
- 第二行是序列号(Sequence number),表示此次发送数据的第一个字节的编号第三行是确认号(Acknowledge number),表示下次想要接收数据的第一个字节的编号。
- 第四行由几个部分组成:
- TCP 头长度(TCP header length),它占4位, 单位是“4字节”,所以我们可以简单计算一下:24*4B=64B(其中有20B 是TCP数据段的头的固定长度,另外 44B 是可选项 Options)。
- 未使用的4位域。
- 8个1位标志:CWR 和 ECE 用作拥塞控制的信号、URG 置1表示使用了紧急指针、 ACK 置1表示确认号字段是有效的、PSH位表示这是带有PUSH 标志的数据、RST 位被用于重置一个己经混乱的连接(一般而言,如果得到的数据段被设置了 RST 位,那说明你这一端有了问题)、SYN被用于建立连接的过程、FIN 被用于释放一个连接。
- 窗口大小(Window size),它表示这个 TCP 数据段发送方当前可用的缓冲区大小,表示的是这一方的接收能力。
- 第五行由两部分组成:第一部分是校验和(Checksum),它校验的范围包括TCP 数据段的头部、数据以及伪TCP头。
- 第六行是 Options。
TCP的校验和需要使用伪TCP头计算,伪TCP头如下图所示:
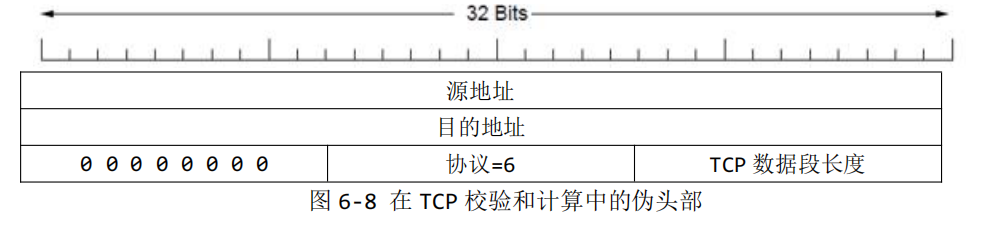
伪 TCP 头的第一行是源地址,第二行是目标地址,第三行由三部分组成:8位0,TCP 的协议号(6)以及TCP 数据段(包括TCP 头)的字节计数。
¶ 连接维护
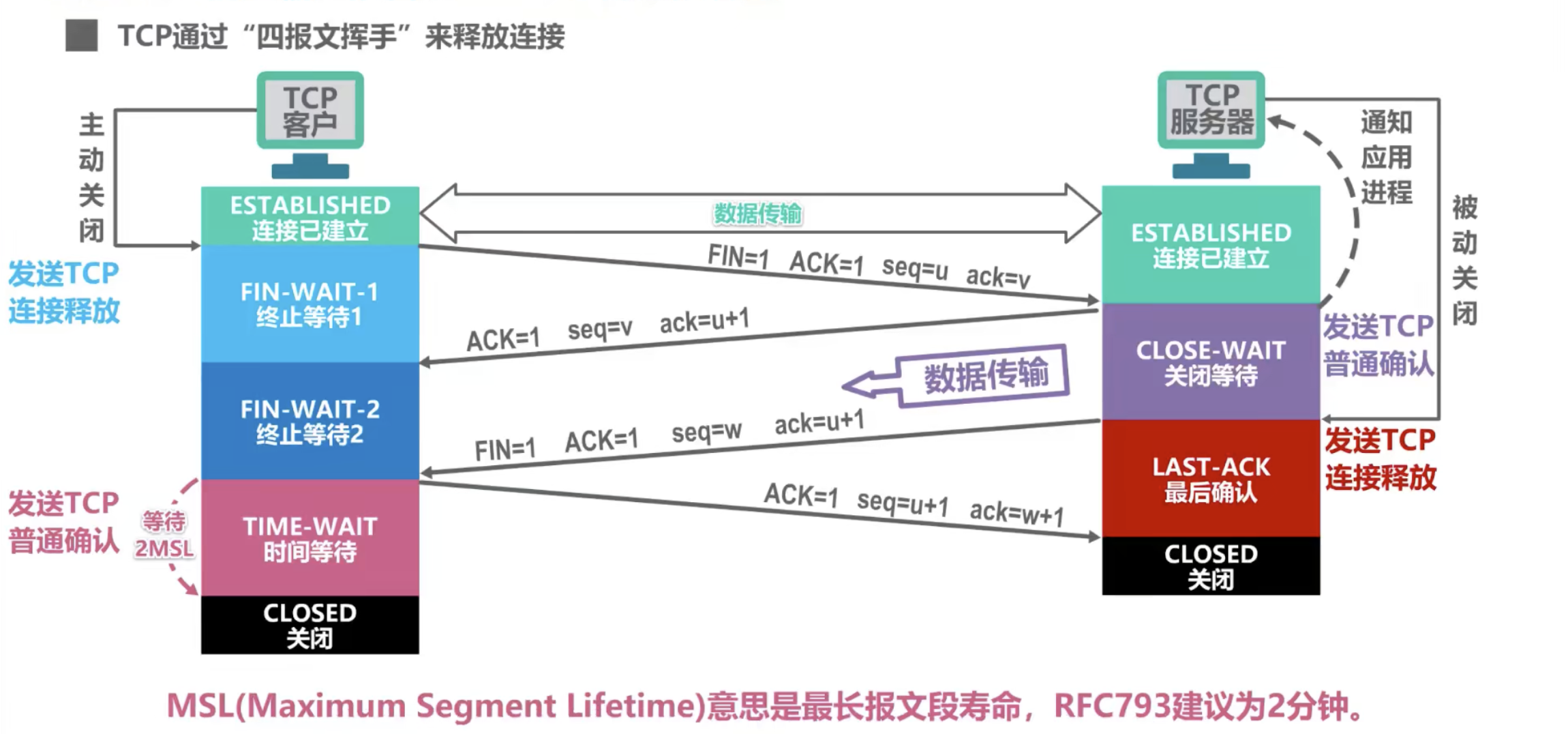
TCP的连接总结为“三次握手四次挥手”。
连接建立过程如下:
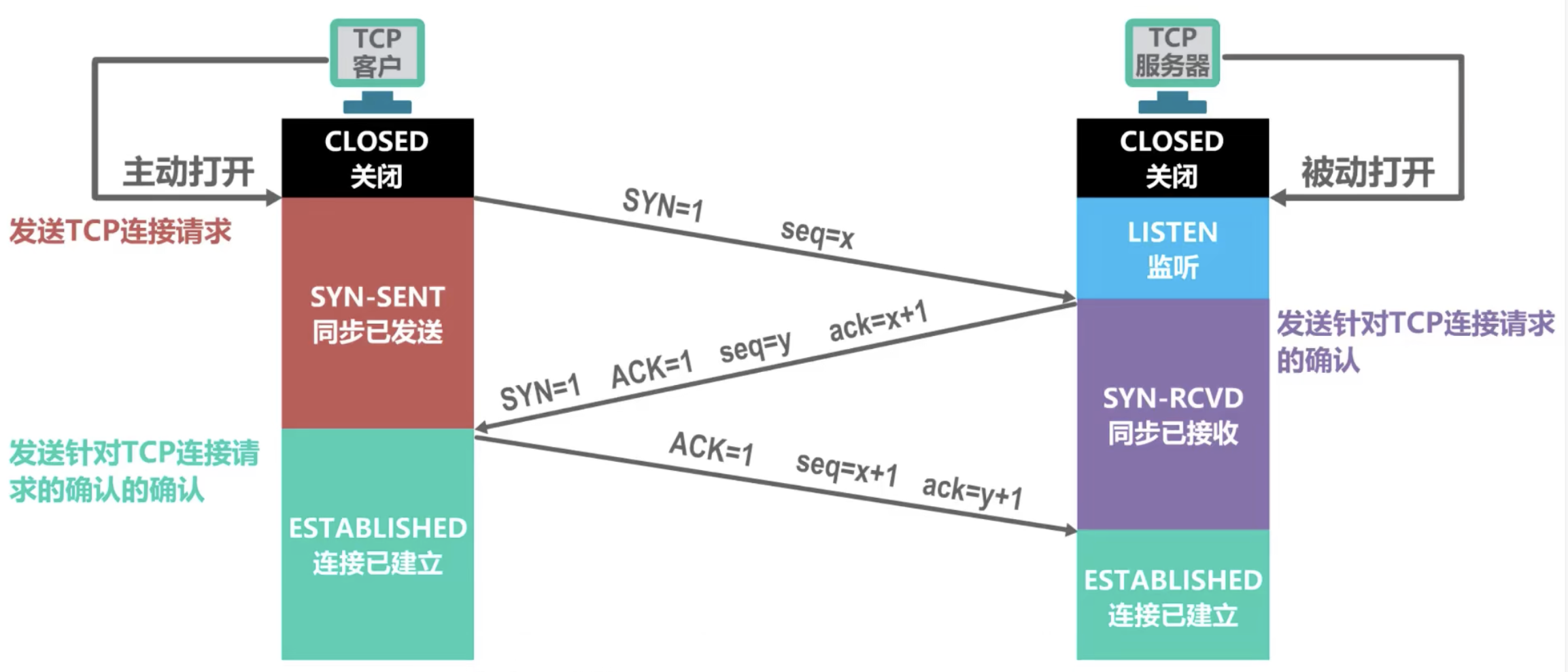
- 客户机的TCP 首先向服务器的 TCP 发送一个连接请求报文。这个特殊的报文段不含应用层数据,但会消耗一个序号。
SYN=1。客户机随机选择一个起始序号seq=x。 - 服务器的 TCP 收到连接请求报文段后,如同意建立连接,就向客户机发回确认,并为该 TCP 连接分配 TCP 缓存和变量。在确认报文段中,
SYN=1,ACK=1,ack=x+1,并且服务器随机产生起始序号seq=y,确认报文同样不包含应用层数据。 - 当客户机收到确认报文后,还要向服务器发出确认,同时也要给该连接分配缓存和变量。
ACK=1,seq=x+1,ack=y+1。该报文可以携带数据,如果不携带数据就不消耗序号。
为何还要进行第二次确认?主要是为了防止已失效的连接请求报文段突然又传到了B,因而产生错误。
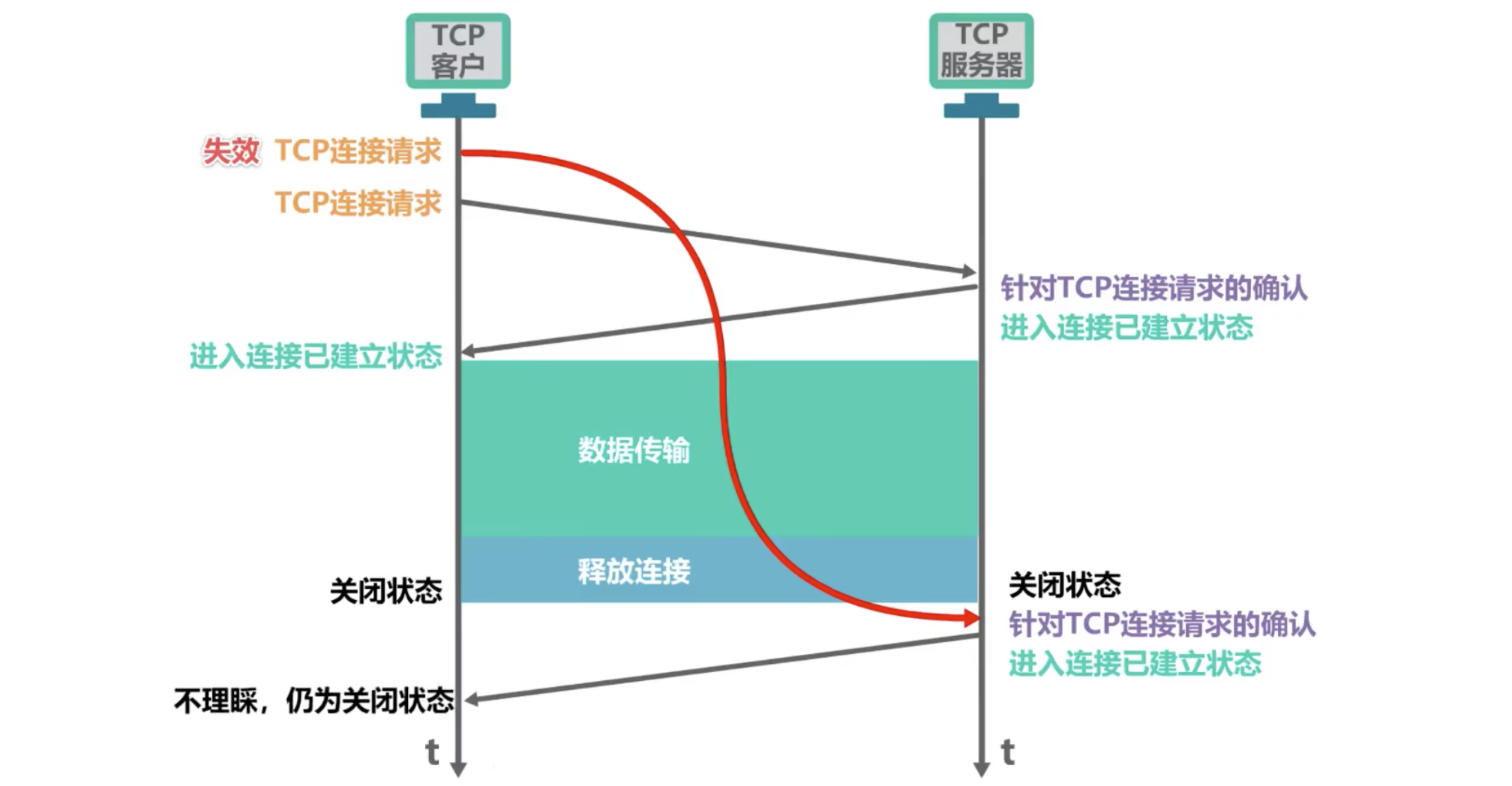
连接过程由四次挥手组成,如果将2、3次挥手进行捎带的话也可以实现三次挥手释放连接。连接释放过程如下:
-
客户机打算关闭连接,就向其 TCP 发送一个连接释放报文段,并停止再发任何数据,主动关闭 TCP 连接,该报文段的
FIN=1,seq=u,它等于前面已传送过的数据的最后一个字节的序号加一(FIN 报文段即使不携带任何数据,但也要消耗掉一个序号)。TCP 是全双工的,即可以想象成一条 TCP 上有两条数据通路。当发送 FIN 报文时,发送 FIN 的一端就不能再发送数据,也就是关闭了其中的一条数据通路,但是对方还可以发送数据。 -
服务器接收到连接释放报文段后即发出确认,确认号是
ack=u+1,而这个报文段自己的序号是v,等于它前面传送过的数据的最后一个字节的序号加 1。此时,从客户及到服务器这个方向的连接就释放了,TCP 连接处于半关闭状态。但服务器若发送数据,客户机仍要接收,即从服务器到客户机这个方向的连接仍未关闭。 -
若服务器已经没有要向客户机发送的数据,就通知 TCP 释放连接,此时发出
FIN=1,ACK=1,seq=w,ack=u+1的连接释放报文段。 -
客户机收到连接释放报文段后,必须发出确认。在确认报文段中,
ACK=1,确认号ack=w+1,序号seq=u+1。此时 TCP 连接还没释放掉,必须经过时间等待计时器设置的时间 2MSL 后,A 才进入到连接关闭状态。
为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
这是因为服务端在 LISTEN 状态下,收到建立连接请求的 SYN 报文后,把 ACK 和 SYN 放在一个报文里发送给客户端。而关闭连接时,当收到对方的 FIN 报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,所以己方可以立即 close,也可以发送一些数据给对方后,再发送 FIN 报文给对方来表示同意现在关闭连接,因此,己方 ACK 和 FIN 一般都会分开发送。
TCP提供的可靠数据传输服务就是要保证接收方进程从缓存区读出的字节流与发送方发出的字节流是完全一样的。TCP使用了校验、序号、确认和重传等机制来达到这个目的:
- 序号:TCP连接中传送的数据流的每一个字节都要编上一个序号。序号字段的值则指的是本报文段发送的数据的第一个字节的序号。
- 确认:TCP首部的确认号是期望收到对方的下一个报文段的数据的第一个字节的序号。TCP使用累计确认,即TCP只确认数据流中至第一个丢失字节为止的字节。
- 重传:超时和冗余ACK会导致重传。
- 超时:TCP每发送一个报文段,就对这个报文段设置一次计时器。只要计时器设置的重传时间到期但还没有收到确认,就重传这一报文段。TCP采用一种自适应算法,它记录一个报文段发出的时间,以及收到相应确认的时间,这两个时间之差叫做报文段的往返时间(RTT)。
- 冗余ACK:TCP规定每当比期望序号大的失序报文段到达时,发送一个冗余ACK,指明下一个期待字节的序号。TCP规定当发送方收到对同一个报文段的3个冗余ACK时,就可以认为跟在这个被确认报文段之后的报文段已经丢失。这时可以立即对丢失的报文段进行重传,这种技术成为快速重传。
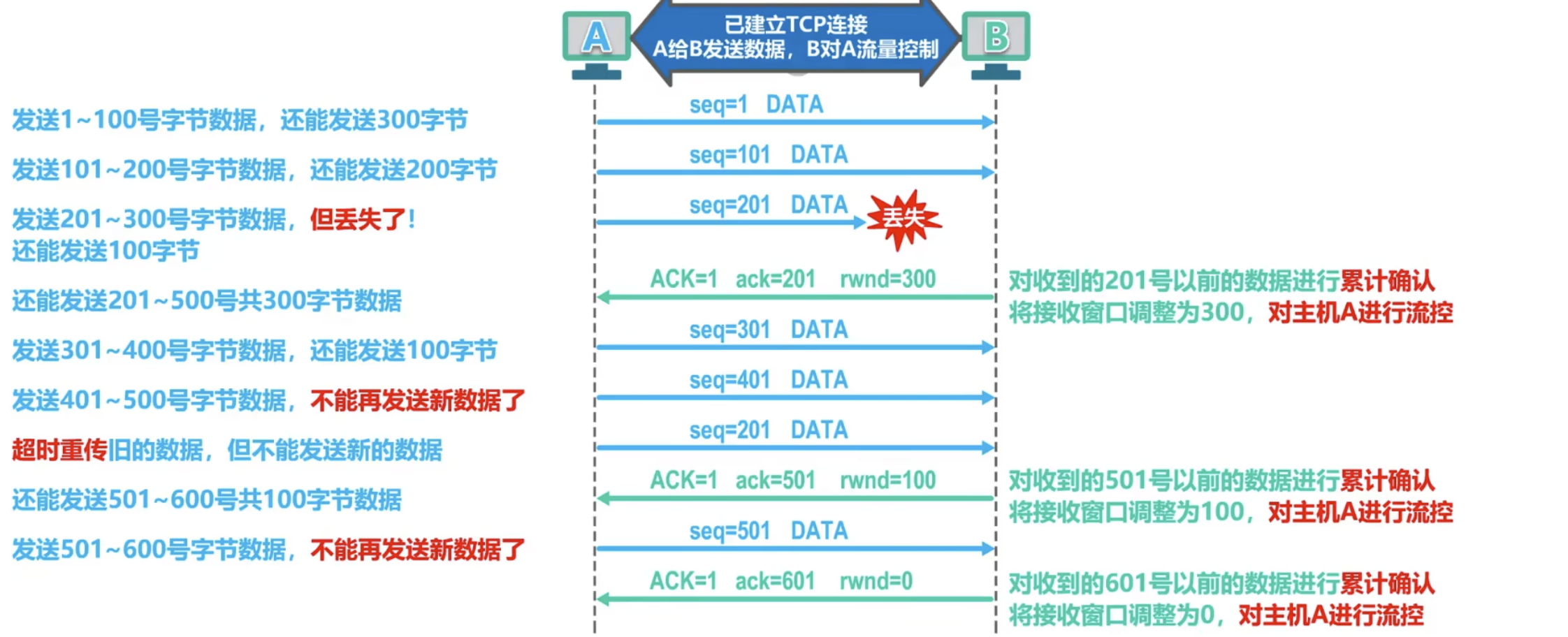
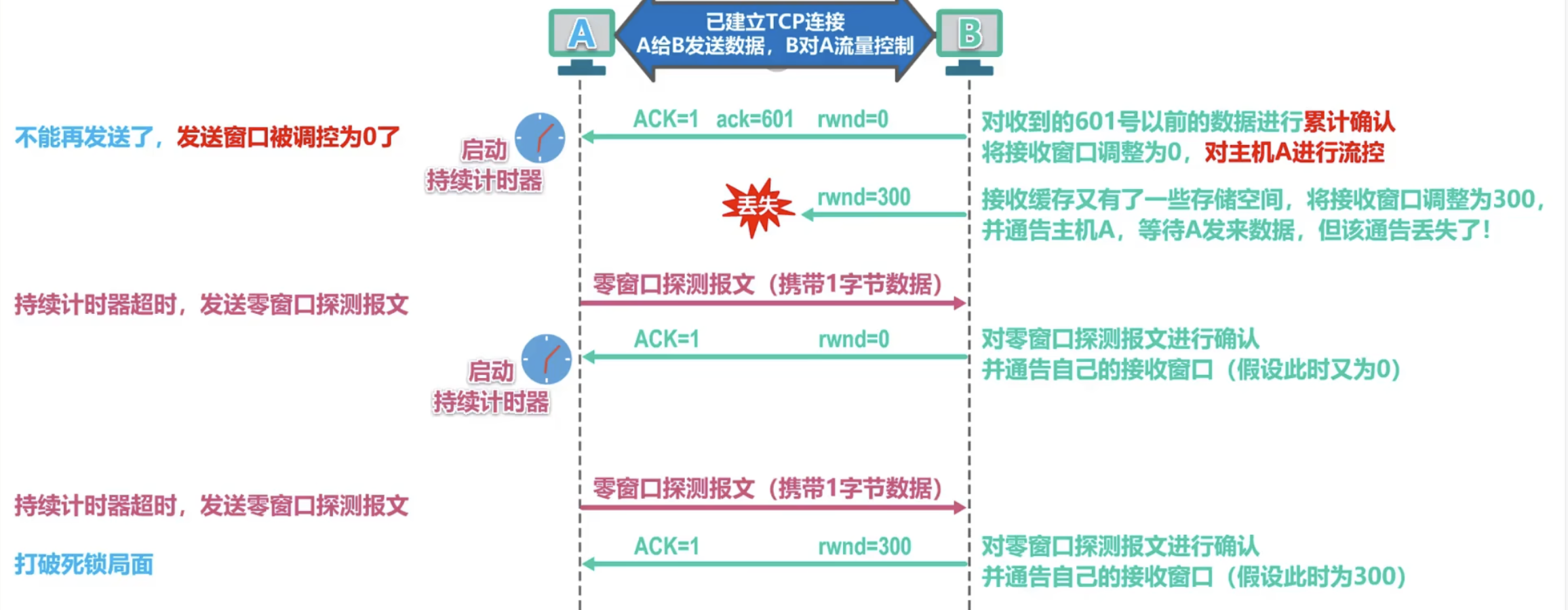
¶ 流量控制
TCP 提供一种基于滑动窗口协议的流量控制机制。在通信过程中,接收方根据自己接收缓存的大小,动态地调整发送方的发送窗口大小,这就是接受窗口 rwnd,即调整 TCP 报文段首部中的“窗口”字段值,来限制发送方向网络注入报文的速率。同时,发送方根据其对当前网络拥塞程度的估计而确定的窗口值,称为拥塞窗口 cwnd,其大小与网络的带宽和时延密切相关。
A 的发送窗口的实际大小是取 rwnd 和 cwnd 中的最小值。
¶ 拥塞控制
在某段时间,若对网络中的某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏,这种情况就要做拥塞。所谓拥塞控制就是防止过多的数据注入网络中,这样可以使网络中的路由器或链路不致过载。
TCP 协议中主要的拥塞控制为慢启动协议和拥塞避免协议,进一步的,还有快速重传和快速恢复协议。
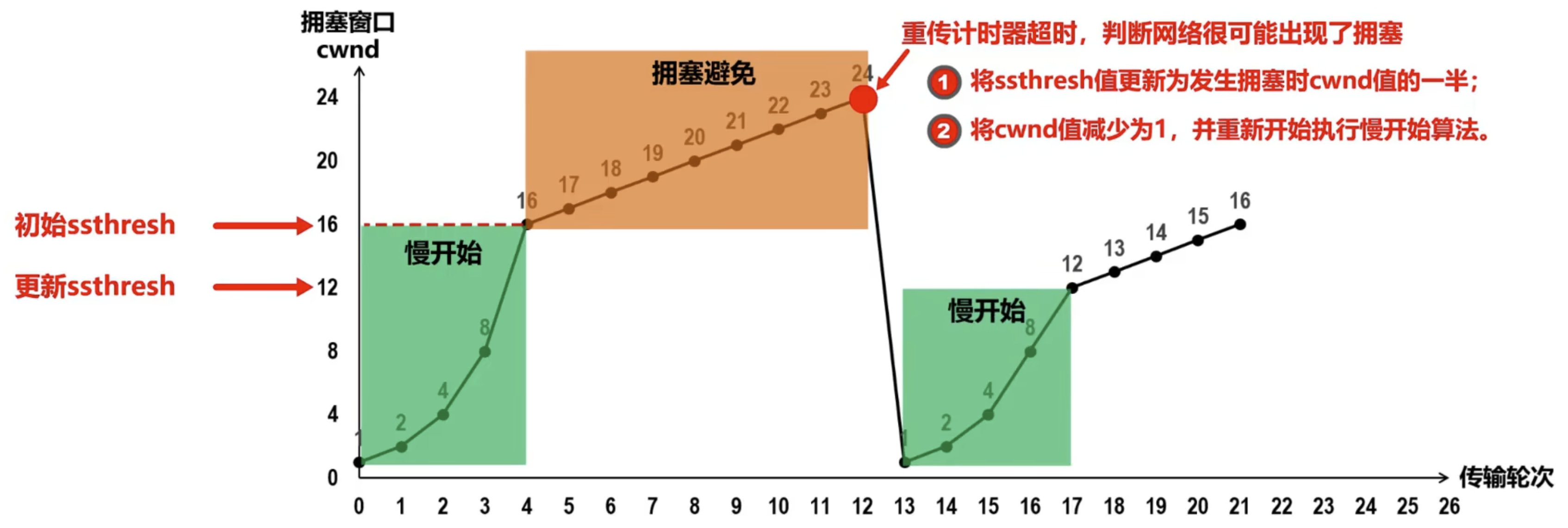
在 TCP 刚刚连接好,开始发送 TCP 报文段时,先令拥塞窗口 cwnd=1,即一个最大报文段长度 MSS。而在每收到一个对新的报文的确认后,将 cwnd 加 1,即增大一个 MSS。用这样的方法逐步增大发送方的拥塞窗口,可以使分组注入网络的速率更加合理。使用慢开始算法后,每经过一个传输轮次(即往返时延 RTT),拥塞窗口 cwnd 就会加倍,即 cwnd 的大小呈指数形式增长。这样慢开始一直把拥塞窗口增大到一个规定的慢开始门限,然后改用拥塞避免算法。
拥塞避免算法的做法是:发送端的拥塞窗口 cwnd 每经过一个往返时延 RTT 就增加一个MSS 的大小而不是加倍,使 cwnd 按线性规律缓慢增长(即加法增大),而当出现一次超时(网络拥塞),则令慢开始门限等于当前 cwnd 的一半(即乘法减小)。
当网络出现拥塞时,无论在慢开始阶段还是拥塞避免阶段,只要发送方检测到超时事件的发生(没有按时收到确认,重传计时器超时),就把慢开始门限设置为出现拥塞时的发送方 cwnd 的一半(但不能小于 2)。然后把拥塞窗口 cwnd 重设为 1,执行慢启动算法。这样做的目的是迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。
¶ 应用层
¶ DNS协议
DNS(Domain Name System)域名系统是因特网使用的命名系统,用来把便于人们记忆的含有特定含义的主机名转换为便于机器处理的 IP 地址。
DNS 系统采用客户/服务器模型,其协议运行在 UDP 之上,使用 53 端口;分为 3 部分:层次域名空间、域名服务器、解析器。
域名解析有两种方式:递归和迭代。
某客户机想知道域名为 y.abc.com 主机的 IP 地址的解析过程:
- 客户机向其本地域名服务器发出 DNS 请求报文。
- 本地域名服务器收到请求后,查询本地缓存,假设没有该记录,则以 DNS 客户的身份向根域名服务器发出解析请求。
- 根域名服务器收到请求后,判断该域名属于.com 域,则将对应的顶级域名服务器 dns.com 的 IP 地址返回给本地域名服务器。
- 本地域名服务器向顶级域名服务器 dns.com 发送解析请求报文。
- 顶级域名系统 dns.com 收到请求后,判断该域名属于 abc.com 域,故将对应的授权域名服务器 dns.abc.com 的 IP 地址返回给本地域名服务器。
- 本地域名服务器向授权域名服务器 dns.abc.com 发送解析请求报文。
- 授权域名服务器 dns.abc.com 收到请求后,将查询结果返回给本地域名服务器。
- 本地域名服务器将查询结果保存到本地缓存,同时返回给客户机。